Density-Based Clustering
데이터의 밀집 지역이 한 클러스터를 구성하며 비교적 비어있는 지역을 경계로 다른 클러스터와 구분합니다.
이 알고리즘은 클러스터가 불규칙하거나 얽혀있을 때나, 노이즈와 아웃아리어가 존재할 때 사용합니다.

DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN은 특성 공간에서 가까이 있는 데이터가 많아 붐비는 지역의 포인트를 찾습니다.
이런 지역을 특성 공간의 밀집 지역이라 합니다.
DBSCAN의 아이디어는 데이터의 밀집 지역이 한 클러스틀 구성하며 비교적 비어있는 지역을 경계로 다른 클러스터와 구분된다는 것입니다.
DBSCAN의 주요 하이퍼파라미터
min_samples와 eps
한 데이터 포인트에서 eps 거리 안에 데이터가 min_samles 개수만큼 들어 있으면 이 데이터 포인트를 핵심 샘플로 분류합니다.
eps보다 가까운 핵심 샘플은 DBSCAN에 의해 동일한 클러스터로 합쳐집니다.
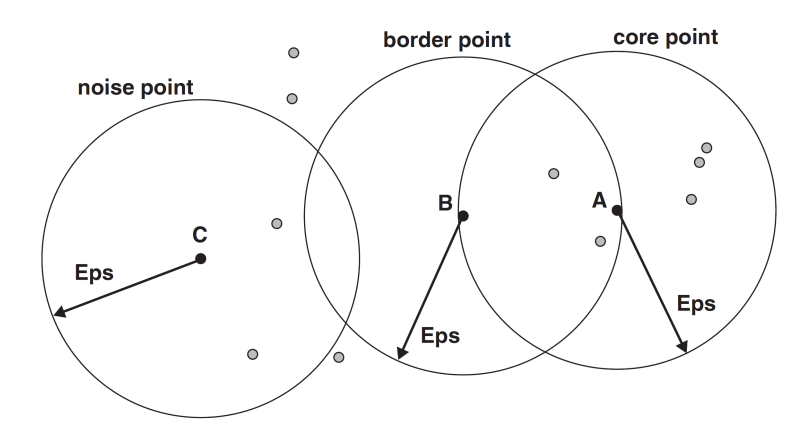
DBSCAN 용어
Density : eps 거리 안에 있는 포인트의 개수
Core point (핵심 포인트) : eps 거리 안에 데이터가 min_samples 개수만큼 들어있는 포인트
Border point (경계 포인트) : 핵심 포인트에서 eps 거리 안에 있는 포인트
Noise Point (잡음 포인트) : 핵심 포인트나 border point에 속하지 않는 포인트
DBSCAN Core, Border, Noise Point (min_samples=7) 예시
DBSCAN 알고리즘
알고리즘은 시작할 때 무작위로 포인트를 선택합니다. 그런 다음 그 포인트에서 eps 거리 안의 모든 포인트를 찾습니다.
만약 eps 거리 안에 있는 포인트 수가 min_samples보다 적다면 그 포인트는 어떤 클래스에도 속하지 않는 잡음으로 레이블합니다.
만약 eps 거리 안에 min_samples보다 많은 포인트가 있다면 그 포인트는 핵심 포인트로 레이블하고 새로운 클러스터 레이블을 할당합니다.
그런 다음 그 포인트의 (eps 거리 안의) 모든 이웃을 살핍니다.
만약 어떤 클러스터에도 할당되지 않았다면 바로 전에 만든 클러스터 레이블을 할당합니다.
만약 핵심 포인트면 그 포인트의 이웃을 차례로 방문합니다.
이런식으로 계속 진행하여 클러스터는 eps 거리 안에 더 이상 핵심 샘플이 없을 때까지 자라납니다.
그런 다음 아직 방문하지 못한 포인트를 선택하여 같은 과정을 반복합니다.
클러스터 수 결정
DBSCAN은 클러스터의 개수를 미리 지정하지 않습니다.
eps를 설정하여 클러스터 수를 암시적으로 통제합니다.
데이터 스케일링 후에 eps 설정을 찾는 것이 더 쉬울 수 있습니다.
Blobs 데이터셋 - DBSCAN
from sklearn.datasets import make_blobs
X_train, _ = make_blobs(random_state=0, n_samples=12)
print("X_train.shape:", X_train.shape)X_train.shape: (12, 2)
Blobs 데이터셋을 불러오고 형태를 확인합니다.
from sklearn.cluster import DBSCAN
dbscan = DBSCAN()
dbscan.fit(X_train)
DBSCAN 객체를 만들고 모델을 생성합니다.
assignments_X_train = dbscan.labels_
print(assignments_X_train)[-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]
모든 포인트에 잡음 포인트를 의미하는 -1 레이블이 할당되었습니다.
작은 샘플 데이텃셋에 적합하지 않은 eps와 min_samples 기본값 때문입니다.
plt.scatter(X_train[:, 0], X_train[:, 1])
데이터 분포 그림입니다.
Blobs 데이터셋 - DBSCAN 하이퍼 파라미터 변화
mglearn.plots.plot_dbscan()
eps를 증가시키면 하나의 클러스터에 더 많은 포인트가 포함됩니다. 클러스터를 커지게 하지만 여러 클러스터를 하나로 합치게도 만듭니다.
min_samples를 키우면 핵심 포인트 수가 줄어들며 잡음 포인트가 늘어납니다.

이 그래프에서 클러스터에 속한 포인트는 색을 칠하고 잡음 포인트는 하얀색으로 남겨뒀습니다. 핵심 샘플은 크게 표시하고 경계 포인트는 작게 나타냈습니다.
Blobs 데이터셋 - DBSCAN 데이터 스케일링
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
MixMaxScaler로 스케일을 조정해주었습니다.
from sklearn.cluster import DBSCAN
dbscan = DBSCAN()
dbscan.fit(X_train_scaled)
모델을 생성합니다.
assignmnets_X_train_scaled = dbscan.labels_
print(assignmnets_X_train_scaled)[-1 0 0 0 0 0 0 0 0 0 0 0]
결론
DBSCAN의 주요 하이퍼파라미터
eps, min_samples
metric (distance metric)
데이터 전처리를 하는 것이 중요합니다.
장점
클러스터의 개수를 미리 지정할 필요가 없습니다.
복잡한 형상도 찾을 수 있습니다.
어떤 클래스에도 속하지 않은 포인트를 구분할 수 있고 아웃라이어에 로버스트 합니다.
단점
전적으로 결정적인건 아닙니다.
밀도 차이가 크면 데이터를 잘 클러스터링 할 수 없습니다.
고차원 데이터에서 잘 작동하지 않습니다.
성능이 데이터 스케일링에 매우 의존합니다.
파이썬 라이브러리를 활용한 머신러닝 책과 성균관대학교 강석호 교수님 수업 내용을 바탕으로 요약 작성되었습니다.
'파이썬 라이브러리를 활용한 머신러닝' 카테고리의 다른 글
| Categorical Variables (0) | 2019.12.04 |
|---|---|
| Comparing and Evaluating Clustering Algorithms (0) | 2019.12.02 |
| Hierarchical Clustering (0) | 2019.11.26 |
| K-Means Clustering (0) | 2019.11.25 |
| t-distributed Stochastic Neighbor Embedding (0) | 2019.11.19 |




댓글