계층적 군집 (Hierarchical Clustering)
계층적 군집은 계층 트리로 조직화된 내포된 클러스터의 셋(set)을 만듭니다. 덴드로그램으로 시각화할 수 있습니다.
덴드로그램은 일련의 병합이나 분할을 기록한 트리 다이어그램입니다.

계층적 군집의 두가지 주요 유형
1. 병합 군집 (Agglomerative clustering, 가장 유명함)
시작할 때 각 포인트를 하나의 클러스터로 지정합니다.
어떤 종료 조건을 만족할 때까지 가장 비슷한 두 클러스터를 합쳐나갑니다.
2. 분리 군집 (Divisive clustering)
하나의 포괄적인 클러스터로 시작합니다 (전체 데이터셋이 하나의 클러스터)
어떤 종료 조건을 만족할 때까지 클러스터를 분할합니다.
병합 군집
병합 군집은 다음과 같은 원리로 만들어진 군집 알고리즘의 모음을 말합니다.
시작할 때 각 포인트를 하나의 클러스터로 지정하고, 그다음 어떤 종료 조건을 만족할 때까지 가장 비슷한 두 클러스터를 합쳐나갑니다.
병합 군집의 예시
처음에는 각 포인트가 하나의 클러스터입니다.
각 단계에서 가장 가까운 두 클러스터가 합쳐집니다.

병합 군집 - 클러스터 수 결정
덴드로그램은 클러스터들이 합쳐진 모습을 볼 수있게 도와줍니다.
각 중간 단계는 데이터의 클러스터링을 만듭니다 (클러스터의 수가 다름)
수평선은 멀리 떨어진 클러스터를 교차하면서 클러스터를 구분합니다.

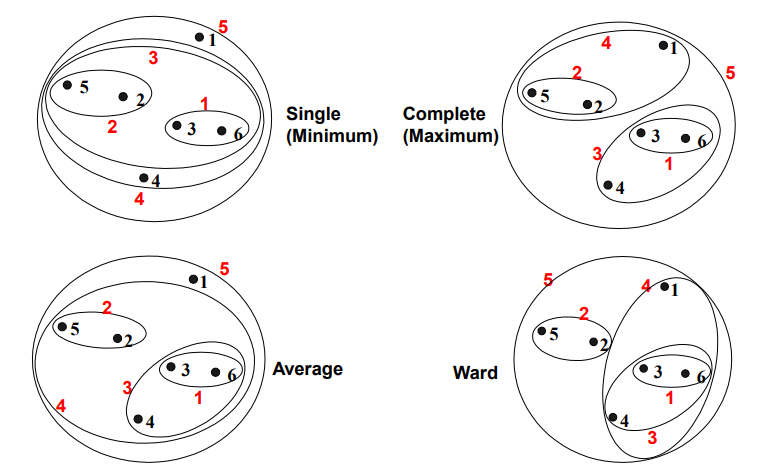
병합 군집 - linkage 옵션
linkage 옵션에서 가장 비슷한 클러스터를 측정하는 방법을 제시합니다. 이 측정은 항상 두 클러스터 사이에서 이뤄집니다.
Single (Minimum), Complete (Maximum), Average, Ward

Ward가 대부분의 데이터셋에 알맞습니다.
클러스터에 속한 포인트 수가 많이 다를 때는 (예를 들면 한 클러스터가 다른 것보다 매우 클 때) average나 complete가 더 나을 수 있습니다.
Single (Minimum) Linkage
클러스터 포인트 사이의 최소 거리가 가장 짧은 두 클러스터를 합칩니다.
비 타원 모양을 다룰 수 있습니다.
노이즈나 아웃라이어에 민감합니다.

Complete (Maximum) Linkage
클러스터 포인트 사이의 최대 거리가 가장 짧은 두 클러스터를 합칩니다.

Average Linkage
클러스터 포인트 사이의 평균 거리가 가장 짧은 두 클러스터를 합칩니다.
Single과 Complete Linkage의 타협입니다.
노이즈나 아웃라이어에 덜 취약합니다.
globular clustes 편향

Ward Linkage
모든 클러스터 내의 분산을 가장 작게 증가시키는 두 클러스터를 합칩니다.
노이즈나 아웃라이어에 덜 취약합니다.
globular clustes 편향
크기가 비교적 비슷한 클러스터가 만들어집니다.
K-평균의 계층적 유사입니다.
사이킷 런의 기본 값입니다.
다른 Linkage 옵션의 병합 군집 예시
Blobs Dataset 예시 - AgglomerativeClustering
from sklearn.datasets import make_blobs
X_train, _ = make_blobs(random_state=1)
print("X_train.shape :", X_train.shape)X_train.shape : (100, 2)
데이터셋을 불러오고 형태를 확인합니다.
from sklearn.cluster import AgglomerativeClustering
agg = AgglomerativeClustering(n_clusters=3)
agg.fit(X_train)
훈련 세트로 모델을 만듭니다.
assignments_X_train = agg.labels_
print(assignments_X_train)
labels_ 속성을 사용하여 반환합니다.

아이리스 데이터셋 예시 - Different Linkages
from sklearn.datasets import load_iris
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import adjusted_rand_score
iris = load_iris()
X_train, y_train = iris.data, iris.target
print("X_train.shape :", X_train.shape)X_train.shape : (150, 4)
아이리스 데이터셋을 불러오고 형태를 확인합니다.
clustering_ari = []
linkage_settings = ['ward', 'average', 'single', 'complete']
for linkage in linkage_settings:
# build the model
agg = AgglomerativeClustering(n_clusters=3, linkage=linkage)
agg.fit(X_train)
# adjusted_random_index on the training set
assignments_X_train = agg.labels_
clustering_ari.append(adjusted_rand_score(y_train, assignments_X_train))
linkage 옵션을 다르게 해서 ARI를 측정합니다.
d = {'linkage' : linkage_settings, 'ARI': clustering_ari}
pd.DataFrame(d)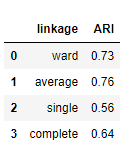
Average가 가장 높고 single이 가장 낮습니다.
결론
계층적 군집의 주요 하이퍼파라미터
affinity, linkage (클러스터 간 거리를 측정)
n_clusters or distance_threshold (종료 조건)
장점
계층적 군집은 서로 다른 레벨의 클러스터링을 시각적으로 표현(덴드로그램)할 수 있으며, 의미 있는 분류법입니다.
특정 수의 클러스터를 가정하지 않습니다.
단점
반복할 수 없기 때문에 불안정합니다 즉, 두 클러스터를 합치기로 결정했으면 돌이킬 수 없습니다.
계산하는데 시간 소모가 큽니다.
성능이 데이터 스케일링에 매우 의존합니다.
복잡한 형상을 구분하지 못합니다.
파이썬 라이브러리를 활용한 머신러닝 책과 성균관대학교 강석호 교수님 수업 내용을 바탕으로 요약 작성되었습니다.
'파이썬 라이브러리를 활용한 머신러닝' 카테고리의 다른 글
| Comparing and Evaluating Clustering Algorithms (0) | 2019.12.02 |
|---|---|
| DBSCAN (0) | 2019.11.28 |
| K-Means Clustering (0) | 2019.11.25 |
| t-distributed Stochastic Neighbor Embedding (0) | 2019.11.19 |
| Principal Component Analysis (0) | 2019.11.18 |




댓글