특성 공학 (Feature Engineering)
특정 어플리케이션에 가장 적합한 데이터 표현을 찾는 것을 특성 공학이라합니다.
데이터 과학자와 머신러닝 기술자가 실제 문제를 풀기 위해 당면하는 주요 작업 중 하나입니다.
올바른 데이터 표현은 지도 학습 모델에서 적절한 하이퍼파라미터를 선택하는 것보다 성능에 더 큰 영향을 미칩니다.
트리 기반 모델은 특성의 순서에만 영향을 받지만 선형 모델과 신경망은 각 특성의 스케일과 분포에 밀접하게 연관되어 있습니다.
범주형 변수 (Categorical Variables) - adult 데이터셋
adult 데이터셋은 1994년 인구 조사 데이터베이스에서 추출한 미국 성인의 소득 데이터셋입니다.
이 데이터셋을 사용해 어떤 근로자의 수입이 50,000달러를 초과하는지, 그 이하일지를 예측하려고 합니다.
데이터셋에는 근로자 나이, 고용형태, 교육 수준, 성별, 주당 근로시간, 직업 등의 특성이 있습니다.
age와 hours-per-week는 연속형 특성입니다.
workclass, education, sex, occupation은 범주형 특성입니다. 이런 특성들은 어떤 범위가 아닌 고정된 목록 중 하나를 값으로 가지며, 정량적이 아니고 정성적인 속성입니다.

Adult 데이터셋 - Pandas Practice
import mglearn, os
adult_path = os.path.join(mglearn.datasets.DATA_PATH, "adult.data")
print(adult_path)
데이터를 load합니다.
import pandas as pd
# 이 파일은 열 이름을 나타내는 헤더가 없으므로 header=None으로 지정하고
# "names" 매개변수로 열 이름을 제공합니다
data = pd.read_csv(
adult_path, header=None, index_col=False,
names=['age', 'workclass', 'fnlwgt', 'education', 'education-num',
'marital-status', 'occupation', 'relationship', 'race', 'gender',
'capital-gain', 'capital-loss', 'hours-per-week', 'native-country',
'income'])
display(data.head())
adult 데이터셋의 처음 5개의 row를 보여줍니다.
# 예제를 위해 몇개의 열만 선택합니다
data = data[['age', 'workclass', 'education', 'gender', 'hours-per-week',
'occupation', 'income']]
# IPython.display 함수는 주피터 노트북을 위해 포맷팅된 출력을 만듭니다
display(data.head())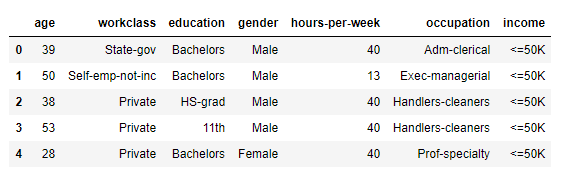
몇 개의 열만 선택합니다.
age와 hours-per-week는 연속형 특성입니다.
workclass, education, sex, occupation은 범주형 특성입니다.
print(data.income.value_counts())
print(data.gender.value_counts())
print(data.workclass.value_counts())
먼저 열에 어떤 의미 있는 범주형 데이터가 있는지 확인해보는 것이 좋습니다.
column의 내용을 확인하는 좋은 방법은 pandas의 value_counts 사용하는 것입니다.
value_counts는 unique 변수와 개수를 알려줍니다.
원-핫-인코딩 (One-Hot Encoding, 가변수)
k-NN, linear models, SVM, neural networks 같은 알고리즘을 적용할 때, 범주형 변수는 반드시 숫자형으로 바꿔주어야 합니다.
범주형 변수를 표현하는 데 가장 널리 쓰이는 방법은 원-핫-인코딩입니다. 가변수 (dummy variable)라고도 합니다.
가변수는 범주형 변수를 0 또는 1 값을 가진 하나 이상의 새로운 특성으로 바꾼 것입니다.
Adult 데이터셋 - Pandas Practice
data_dummies = pd.get_dummies(data)
display(data_dummies.head())
Pandas의 get_dummies 함수는 객체 타입(문자열 같은)이나 범주형을 가진 열을 자동으로 변환해줍니다.
연속형 특성인 age와 hours-per-week는 그대로지만 범주형 특성은 값마다 새로운 특성으로 확장되었습니다.
X = data_dummies.loc[:, 'age':'occupation_ Transport-moving'].values
y = data_dummies['income_ >50K'].values
print("X.shape: {} y.shape: {}".format(X.shape, y.shape))X.shape: (32561, 44) y.shape: (32561,)
특성 age부터 occupation_Transport-moving까지 모든 열을 추출합니다. 타깃을 뺀 모든 특성이 포함됩니다.
data_dummies = pd.get_dummies(data, columns=['age', 'workclass'])
display(data_dummies.head())
범주형 특성은 종종 숫자로 인코딩됩니다. 특성의 값이 숫자라고 해서 연속형 특성으로 다뤄야 한다는 의미는 아닙니다.
숫자 특성도 가변수로 만들고 싶다면 columns 매개변수에 인코딩하고 싶은 열을 명시해야합니다.
파이썬 라이브러리를 활용한 머신러닝 책과 성균관대학교 강석호 교수님 수업 내용을 바탕으로 요약 작성되었습니다.
'파이썬 라이브러리를 활용한 머신러닝' 카테고리의 다른 글
| Polynomials and Interactions (0) | 2019.12.06 |
|---|---|
| Binning (Discretization) (0) | 2019.12.06 |
| Comparing and Evaluating Clustering Algorithms (0) | 2019.12.02 |
| DBSCAN (0) | 2019.11.28 |
| Hierarchical Clustering (0) | 2019.11.26 |




댓글