비지도 학습
일반적으로 레이블이 없는 훈련 데이터셋 $D = \left \{ \mathbf{x_{1}}, \mathbf{x_{2}}, ..., \mathbf{x_{n}} \right \}$,
각 데이터 포인트 $\mathbf{x_{i}} \in R^{d}$는 d개의 특성 $\mathbf{x_{i}} = (x_{i}^{1}, ..., x_{i})^{d}$을 포함합니다.
데이터셋 구조에서 유용한 속성이나 패턴을 찾아야 합니다.
레이블이 없는 데이터셋

비지도 학습이란 알고 있는 출력값이나 정보 없이 학습 알고리즘을 가르쳐야 하는 모든 종류의 머신러닝을 가리킵니다.
비지도 학습은 보통 레이블이 없는 데이터에 작용하기 때문에 무엇이 올바른 출력인지 모릅니다. 그래서 어떤 모델이 일을 잘하고 있는지 일야기하기가 매우 어렵습니다.
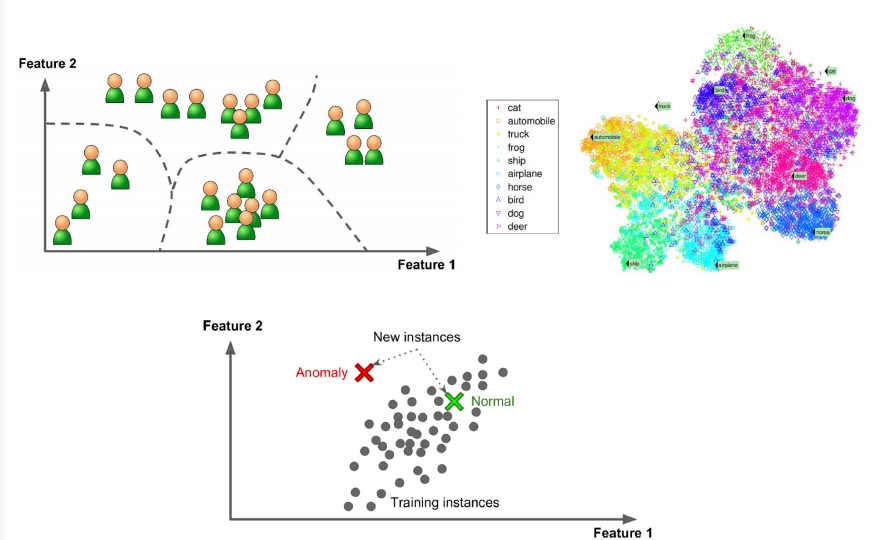
비지도 학습의 종류
비지도 변환
데이터를 새롭게 표현하여 사람이나 다른 머신러닝 알고리즘이 원래 데이터보다 쉽게 해석할 수 있도록 만드는 알고리즘입니다.
데이터를 구성하는 단위나 성분을 찾기도 합니다.
차원 축소
특성이 많은 고차원 데이터를 특성의 수를 줄이면서 꼭 필요한 특징을 포함한 데이터로 표현하는 방법입니다.
대표적인 예는 시각화를 위해 데이터셋을 2차원으로 변경하는 경우입니다.
군집 알고리즘
데이터를 비슷한 것끼리 그룹으로 묶습니다.
이상 감지 (Anomaly Detection (One-Class Classification)), 연관성 분석 (Association Analysis)
비지도 학습의 도전 과제
비지도 학습에서 가장 어려운 일은 알고리즘이 뭔가 유용한 것을 학습했는지 평가하는 것입니다.
무엇이 올바른 출력인지 모릅니다.
비지도 학습 알로리즘의 하이퍼파라미터를 튜닝하는 것은 매우 어렵습니다.
결과를 평가하기 위해서는 직접 확인하는 것이 유일한 방법일 때가 많습니다.
비지도 학습 알고리즘은 탐색적 셋팅에서 사용됩니다.
데이터 과학자가 데이터를 더 잘 이해하고 싶을 때 사용합니다.
지도 학습을 위한 전처리
비지도 학습은 지도 학습의 전처리 단계에서도 사용합니다.
비지도 학습의 결과로 새롭게 표현된 데이터를 사용해 학습하면 지도 학습의 정확도가 좋아지기도 하며
메모리와 시간을 절약할 수 있습니다.
k-최근접 이웃, 서포트 벡터 머신, 신경망 같은 몇몇 지도 학습 알고리즘은 에이터 스케일에 매우 민감합니다.
여러 가지 전처리 방법
보통 알고리즘에 맞게 데이터 특성 값을 조정합니다. 즉, 특성마다 스케일을 조정해서 데이터를 변경합니다.
데이터를 기준이 되는 범위로 변환하는 방법이 있습니다.
StandardScaler는 각 특성의 평균을 0, 분산을 1로 변경하여 모든 특성이 같은 크기를 가지게 합니다.
MinMaxScaler는 모든 특성이 정확하게 0과 1 사이에 위치하도록 데이터를 변경합니다.
mglearn.plots.plot_scaling()
두 개의 특성을 인위적으로 만든 이진 분류 데이터셋의 전처리를 하는 여러 방법입니다.
유방암 데이터셋 - StandardScaler
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
유방암 데이터셋을 이용하겠습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=1)
훈련 세트와 테스트 세트로 나눠줍니다.
X_train_pd = pd.DataFrame(X_train)
X_train_pd.head()
훈련 세트의 X를 데이터프레임으로 나타냈습니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
StandardScaler에 훈련 데이터를 적용합니다.
X_train_scaled_pd = pd.DataFrame(X_train_scaled)
X_train_scaled_pd.head()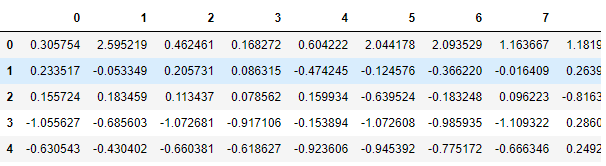
배열 크기는 원래 데이터와 동일하지만 데이터는 스케일 되었습니다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
MinMaxScaler을 써서 스케일 해주겠습니다.
X_train_scaled_pd = pd.DataFrame(X_train_scaled)
X_train_scaled_pd.head()
모든 특성의 값은 0과 1 사이가 되었습니다.
유방암 데이터셋 - 데이터 전처리 전후 효과 비교하기
SVC를 학습시킬 때 MinMaxScaler의 효과를 확인하겠습니다.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=0)
유방암 데이터셋을 이용하고, 훈련 세트와 테스트 세트로 나눠줍니다.
clf = SVC(C=100)
C를 100으로 설정했습니다.
clf.fit(X_train, y_train)
모델을 학습시킵니다.
y_train_hat = clf.predict(X_train)
print('train accuracy :', accuracy_score(y_train, y_train_hat))
y_test_hat = clf.predict(X_test)
print('test accuracy :', accuracy_score(y_test, y_test_hat))
테스트 세트의 정확도는 0.63으로 나왔습니다.
SVC 모델을 학습시키기 전에 StandardScaler을 사용해 데이터 스케일을 조정합니다.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, random_state=0)
유방암 데이터셋을 이용하고, 훈련 세트와 테스트 세트로 나눠줍니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
StandardScaler를 사용해 데이터의 스케일을 조정합니다.
clf = SVC(C=100)
clf.fit(X_train_scaled, y_train)
모델을 만듭니다.
y_train_hat = clf.predict(X_train_scaled)
print('train accuracy :', accuracy_score(y_train, y_train_hat))
y_test_hat = clf.predict(X_test_scaled)
print('test accuracy :', accuracy_score(y_test, y_test_hat))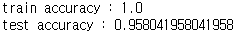
테스트 세트 정확도가 0.96으로 스케일 조정의 효과가 꽤 큽니다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
이번에는 MinMaxScaler를 사용해 데이터의 스케일을 조정합니다.
clf = SVC(C=100)
clf.fit(X_train_scaled, y_train)
모델을 만듭니다.
y_train_hat = clf.predict(X_train_scaled)
print('train accuracy :', accuracy_score(y_train, y_train_hat))
y_test_hat = clf.predict(X_test_scaled)
print('test accuracy :', accuracy_score(y_test, y_test_hat))
역시 테스트 세트의 정확도는 0.97정도로 효과가 꽤 큰 것을 알 수 있습니다.
파이썬 라이브러리를 활용한 머신러닝 책과 성균관대학교 강석호 교수님 수업 내용을 바탕으로 요약 작성되었습니다.
'파이썬 라이브러리를 활용한 머신러닝' 카테고리의 다른 글
| t-distributed Stochastic Neighbor Embedding (0) | 2019.11.19 |
|---|---|
| Principal Component Analysis (0) | 2019.11.18 |
| Uncertainty Estimates from Classifiers & Summary and Outlook (0) | 2019.11.15 |
| Neural Networks (0) | 2019.11.14 |
| Support Vector Machines (0) | 2019.11.13 |




댓글