불확실성 추정
어떤 테스트 포인트에 대해 분류기가 예측한 클래스가 무엇인지 뿐만 아니라 정확한 클래스임을 얼마나 확신하는지가 중요할 때가 많습니다.
실제 애플리케이션에서는 오류의 종류에 따라 전혀 다른 결과를 만듭니다.
예를 들어 암을 진료하는 의료 애플리케이션을 생각해보겠습니다.
거짓 양성 예측은 환자에게 추가 진료를 요구하겠지만
거짓 음성 예측은 심각한 질병을 치료하지 못하게 만들 수 있습니다.
대부분의 분류 클래스는 불확실성을 추정할 수 있는 함수를 제공합니다.
아이리스 데이터셋
아이리스 데이터셋을 사용합니다.
세 개의 클래스를 가진 150개의 데이터 포인트로 이루어져 있습니다 (각 클래스당 50개). 4개의 입력 변수가 있습니다. (다중 클래스 분류)
입력 변수는 꽃잎의 길이, 꽃잎의 폭, 꽃받침의 길이, 꽃받침의 폭입니다. 센티미터 단위로 측정하였습니다.
각 포인트는 setosa, versicolor, virginica 중 하나에 속합니다.
목표는 어떤 품종인지 구분해놓은 측정 데이터를 이용해 새로 채집한 붓꽃의 품종을 예측하는 머신러닝 모델을 만드는 것입니다.
아이리스 데이터셋 - predict_proba
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, random_state=42)
아이리스 데이터셋을 불러오고
훈련 데이터와 테스트 데이터로 나누어줍니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
데이터 스케일링을 해줍니다.
from sklearn.neural_network import MLPClassifier
clf = MLPClassifier(max_iter=1000, random_state=0)
clf.fit(X_train_scaled, y_train)
MLPClassifier를 사용하겠습니다.
y_test_hat = clf.predict(X_test_scaled)
y_test_hat = pd.DataFrame({'y_hat' : y_test_hat})
y_test_hat
MLPClassifier가 예측한 결과를 데이터프레임으로 나타냈습니다.
y_test_score = clf.predict_proba(X_test_scaled)
y_test_score = pd.DataFrame(y_test_score)
y_test_score
predict_proba의 출력은 각 클래스에 대한 확률입니다.
임계값 (Cut-off Value)
20개의 데이터 포인트의 이진 분류에서 다양한 cut-off 값이 있습니다.
$p(y = 1 \mid \mathbf{x})$, 클래스 "1"에 속할 확률을 계산합니다.
cut-off 값을 비교하고 결과를 분류합니다
대부분의 케이스에서 default cut-off 값은 0.5입니다.

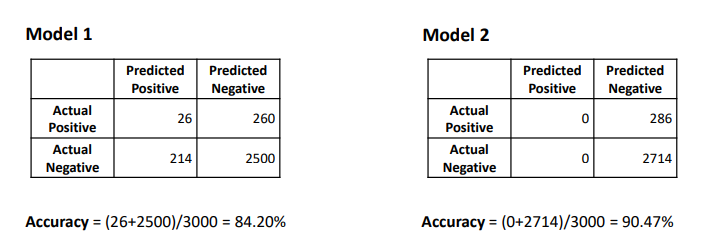
3000개의 데이터 포인트의 이진 분류에서 다른 2개의 cut-off 값을 주고 accuracy를 계산했습니다.
ROC
Receiver Operationg Characteristic (ROC) Curve : 여러 임계값에서 분류기의 튻어을 분석하는 데 널리 사용되는 도구입니다. (plotting sensitivity against 1-specificity at various cut-off values)
AUROC : Area under the ROC curve
불균형한 데이터셋에서 널리 사용됩니다.

Classification with Reject Option
예측 모델의 가변성

Takeaway
중요 용어
일반화 (Generalization)
모델 복잡도 / 과대적합 / 과소적합
규제
파라미터 / 하이퍼파라미터
훈련 / 평가 / 테스트
기억해야할 것
좋은 성능을 위해서는 적절한 하이퍼파라미터를 셋팅하는 것이 중요합니다.
어떤 알고리즘은 입력 데이터에 대해 민감합니다.
모델의 가정과 하이퍼파라미터의 의미를 이해하지 못하고 데이터셋에 아무 알고리즘이나 무조건 적용하면 좋은 모델을 만들 가능성이 낮습니다.
모호한 알고리즘을 잘못 적용하는 것보다 일반적인 알고리즘을 올바르게 적용하는 것이 훨씬 더 도움이 됩니다.
Quick Summary
모델은 관측치의 단순화된 버전입니다 (training data).
단순화는 새로운 데이터로 일반화할 가능성이 없는 불필요한 세부 정보를 삭제하는 것을 말합니다.
그러나 버릴 데이터와 유지할 데이터를 결정하기 위해서는 반드시 가정을 세워야합니다.
예를 들어 선형 모델은 데이터가 근본적으로 선형이며, 인스턴스와 직선 사이의 거리는 노이즈일 뿐이라고 가정합니다.
모델을 언제 사용해야 할까?
최근접 이웃 : 작은 데이터셋일 경우, 기본 모델로서 좋고 설명하기 쉬움
선형 모델 : 첫 번째로 시도할 알고리즘, 대용량 데이터셋 가능. 고차원 데이터에 가능
결정 트리 : 매우 빠름, 테이터 스케일 조정이 필요 없음, 시각화하기 좋고 설명하기 쉬움
랜덤 포레스트 : 결정 트리 하나보다 거의 항상 좋은 성능을 냄, 매우 안정적이고 강력함, 데이터 스케일 조정 필요 없음, 고차원 희소 데이터에는 잘 안 맞음
서포트 벡터 머신 : 비슷한 의미의 특서응로 이뤄진 중간 규모 데이터셋에 잘 맞음, 데이터 스케일 조정 필요, 하이퍼파라미터에 민감
신경망 : 특별히 대용량 데이터셋에서 매우 복잡한 모델을 만들 수 있음, 하이퍼파라미터 선택과 테이터 스케일에 민감, 큰 모델은 학습이 오래 걸림
일반적 가이드라인
새로운 데이터셋으로 작업할 때는 선형 모델이나 최근접 이웃 분류기 같은 간단한 모델로 시작해서 성능이 얼마나 나오는지 가늠해보는 것이 좋습니다.
데이터를 충분히 이해한 뒤에 랜덤 포레스트나 신경망 같은 복잡한 모델을 만들 수 있는 알고리즘을 고려해볼 수 있습니다.
No-Free-Lunch Theorem
No-Free-lunch theorem (Wolpert, 1996), 머신러닝에서 공짜밥은 없다.
데이터에 대해 전혀 가정하지 않는다면, 다른 어떤 모델보다 한 모델을 선호할 이유가 없습니다.
몇몇 데이터셋에서 최상의 모델은 선형 모델일 수 있지만 다른 데이터셋에서는 신경망일 수 있습니다.
더 잘 작동되도록 보장하는 선행 모델은 없습니다.
어떤 모델이 최상이다고 확실하게 말할 수 있는 방법은 그것들을 모두 평가하는 것입니다.
이것이 가능하지 않기 때문에 데이터에 대한 합리적인 가정이 필요하고 그에 따른 몇 개의 합리적인 모델만 평가합니다.
파이썬 라이브러리를 활용한 머신러닝 책과 성균관대학교 강석호 교수님 수업 내용을 바탕으로 요약 작성되었습니다.
'파이썬 라이브러리를 활용한 머신러닝' 카테고리의 다른 글
| Principal Component Analysis (0) | 2019.11.18 |
|---|---|
| Unsupervised Learning & Data Preprocessing (0) | 2019.11.15 |
| Neural Networks (0) | 2019.11.14 |
| Support Vector Machines (0) | 2019.11.13 |
| Decision Trees (0) | 2019.11.12 |




댓글