선형 모델
선형 모델은 입력 특성에 대한 선형 함수를 만들어 예측을 수행합니다.
Linear models for Regression
Linear Regression
Ridge Regression
Lasso Regression
Linear models for Binary Classification
Logistic Regression
선형 회귀(최소제곱법)
회귀의 경우 선형 모델에서 $\hat{y}$은 모델이 만들어낸 예측값입니다.
Linear Regression (ordinary least squares (OLS))
선형 회귀는 예측과 훈련 세트에 있는 타깃 y 사이의 평균제곱오차(mean squared error)를 최소화하는 파라미터 $\textbf{w}$를 찾습니다.
$\hat{y} = w_{0} + w_{1}x^{1} + ... + w_{d}x^{d} = \textbf{w}^{T}\textbf{x} $
$\textbf{x} = (x^{1}, ..., x^{d}) \in R^{d}, \hat{y} \in R$
선형 회귀는 하이퍼파라미터가 없는 것이 장점이지만, 그래서 모델의 복잡도를 제어할 방법도 없습니다.
선형 회귀(최소제곱법) 계속
훈련 데이터 셋
$D = \left \{ (\mathbf{x_{1}}, y_{1}), (\mathbf{x_{2}}, y_{2}), ..., (\mathbf{x_{n}}, y_{n}) \right \}$
$\mathbf{x_{i}} = (1, x_{i}^{1}, ..., x_{i}^{d}) \in R^{d+1}$는 입력 변수 d의 i번째 입력 벡터(vector)이고
$y_{i} \in R$는 대응하는 출력 변수의 레이블입니다.
첫 번째 entry는 항상 1로 설정합니다.
선형 회귀의 출력 (y 예측)
$\hat{y} = f(\mathbf{x}) = \mathbf{w}^{T}\mathbf{x}$,
$\mathbf{w} = (w_{0}, w_{1}, ..., w_{d})$는 파라미터의 벡터입니다.
$w_{1}, ..., w_{d}$은 가중치(weights) 또는 계수(coefficients)라고 하며
$w_{0}$은 절편(intercept) 또는 편향(bias)라고 합니다.
훈련 : training error를 최소화하는 최적의 파라미터 $\mathbf{w}^{*}$를 찾습니다. (cost function)
$\jmath(\mathbf{x}) = MSE_{train} = \frac{1}{n}\sum_{(\mathbf{x_{i}}, y_{i}) \in D} (\hat{y_{i}} - y_{i})^{2} = \frac{1}{n} \left \| \mathbf{X}\mathbf{w} - \mathbf{y} \right \|_{2}^{2}$
$\mathbf{X}, \mathbf{y}$는 D의 행렬 표현입니다.
어떻게 찾을 수 있을까요? 그레이언트가 0이 되겠끔 설정합니다. a closed-form solution (normal equation)
$\triangledown_{\mathbf{w}}MSE_{train} = \frac{1}{n} \triangledown_{\mathbf{w}} \left \| \mathbf{X}\mathbf{w} - \mathbf{y} \right \|^{2} = 0$
$\cdots$
$\cdots$
$\cdots$
$\mathbf{w}^{*} = (\mathbf{X}^{T}\mathbf{X})^{-1}\mathbf{X}^{T}\mathbf{y}$
훈련 모델 $f(\mathbf{x}) = \mathbf{w}^{*T}\mathbf{x}$
선형 회귀 예시 - wave 데이터셋
import mglearn
X, y = mglearn.datasets.make_wave(n_samples=60)
wave 데이터셋을 사용합니다.
X_1 = X.reshape(60, )
data = pd.DataFrame({'y' : y,
'x' : X_1})
data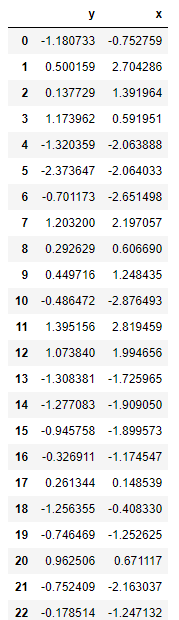
만들어진 데이터셋을 DataFrame 형식으로 나타냈습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
훈련 세트와 테스트 세트로 나누어 주었습니다.
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)
LinearRegression을 임포트하고 객체를 만듭니다. 하이퍼파라미터는 없습니다.
훈련 세트를 사용하여 모델을 학습시킵니다.
y_test_hat = reg.predict(X_test)
print(y_test)
print(y_test_hat)
실제 y와 예측한 y를 나타냈습니다.
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
print('MAE :', mean_absolute_error(y_test, y_test_hat))
print('RMSE :', mean_squared_error(y_test, y_test_hat)**0.5)
print('R_square :', r2_score(y_test, y_test_hat))
테스트 성능을 확인해보면 위와 같습니다. $R^{2}$ 값이 0.66인 것은 그리 좋은 결과는 아닙니다.
print("w0:", reg.intercept_)
print("w1", reg.coef_)
기울기 파라미터(w1)는 reg 객체의 coef_ 속성에 저장되어 있고 절편 파라미터(w0)은 intercept_ 속성에 저장되어있습니다.
선형 함수는 $\hat{y} = -0.0318 + 0.3939x이 됩니다.
mglearn.plots.plot_linear_regression_wave()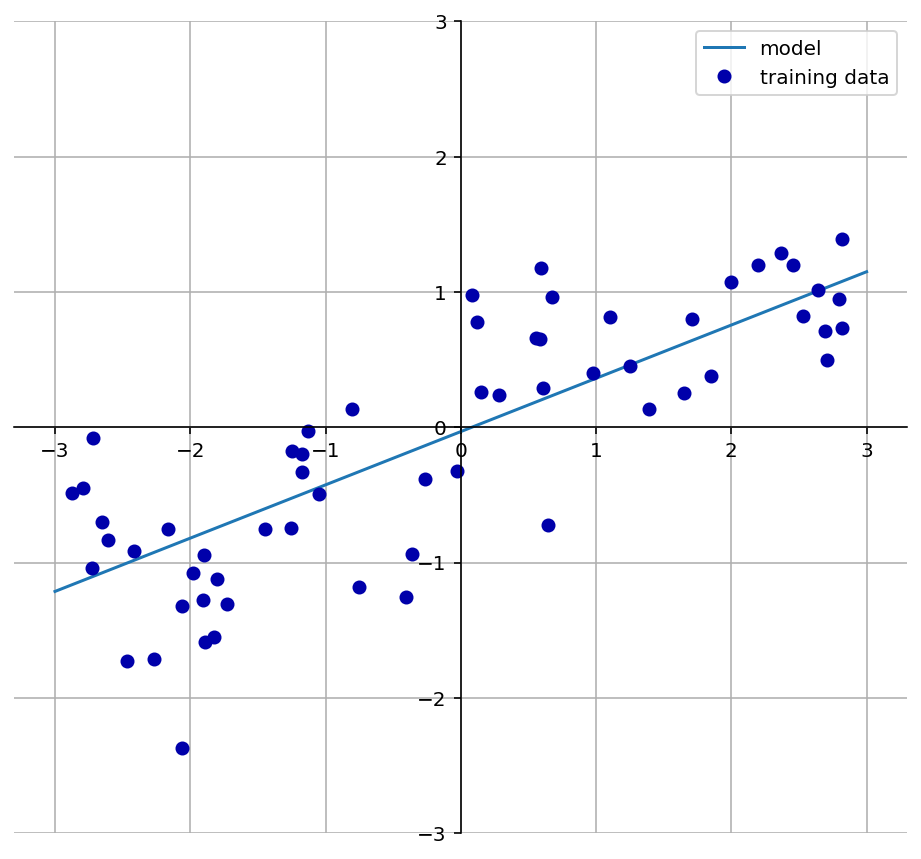
그래프로 확인합니다.
y_train_hat = reg.predict(X_train)
print('MAE :', mean_absolute_error(y_train, y_train_hat))
print('RMSE :', mean_squared_error(y_train, y_train_hat)**0.5)
print('R_square :', r2_score(y_train, y_train_hat))
y_test_hat = reg.predict(X_test)
print('MAE :', mean_absolute_error(y_test, y_test_hat))
print('RMSE :', mean_squared_error(y_test, y_test_hat)**0.5)
print('R_square :', r2_score(y_test, y_test_hat))
훈련 세트와 테스트 세트의 성능은 위와 같습니다.
훈련 세트와 테스트 세트의 점수가 매우 비슷한 것을 알 수 있습니다. 이는 과대적합이 아니라 과소적합인 상태를 의미합니다.
선형 회귀 예시 - 보스턴 주택가격 데이터셋
데이터셋은 샘플이 506개가 있고 입력 변수(특성)은 104개 입니다.
104개의 입력 변수는 13개의 오리지날 변수와 오리지날 변수 13개 안에서 가능한 두 변수의 조합 91개입니다.
import mglearn
X, y = mglearn.datasets.load_extended_boston()
print(X.shape, y.shape)
데이터셋을 읽어들이고 모양을 출력했습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
훈련 세트와 테스트 세트로 나눴습니다.
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)
선형 모델을 만듭니다.
y_train_hat = reg.predict(X_train)
print('MAE :', mean_absolute_error(y_train, y_train_hat))
print('RMSE :', mean_squared_error(y_train, y_train_hat)**0.5)
print('R_square :', r2_score(y_train, y_train_hat))
y_test_hat = reg.predict(X_test)
print('MAE :', mean_absolute_error(y_test, y_test_hat))
print('RMSE :', mean_squared_error(y_test, y_test_hat)**0.5)
print('R_square :', r2_score(y_test, y_test_hat))
훈련 세트와 테스트 세트의 점수를 비교해보면 훈련 세트에서는 예측이 매우 정확한 반면 테스트 세트에서는 $R^{2}$ 값이 매우 낮습니다.
훈련 데이터와 테스트 데이터 사이의 이런 성능 차이는 모델이 과대적합되었다는 확실한 신호입니다.
따라서 복잡도를 제어할 수 있는 모델을 사용해야 합니다.
선형 회귀 규제 - 릿지 회귀
Linear Regression : $\hat{y} = \textbf{W}^{T}\mathbf{x} $
트레이닝 에러를 최소화하는 최적의 파라미터 $\mathbf{w}^{*}$를 찾습니다. (cost function)
$\jmath(\mathbf{w}) = MSE_{train} = \frac{1}{n} \left \| \mathbf{X}\mathbf{w} - \mathbf{y} \right \|^{2}$
Ridge Regression : L2 regularization for linear regression
L2 규제 $\alpha\left \| \mathbf{w} \right \|_{2}^{2}$를 cost function에 더합니다.
$\tilde{\jmath(\mathbf{w})} = MSE_{train} + \alpha\left \| \mathbf{w} \right \|_{2}^{2} = \frac{1}{n} \left \| \mathbf{X}\mathbf{w} - \mathbf{y} \right \|^{2} + \alpha\left \| \mathbf{w} \right \|_{2}^{2}$
Lasso Regression : L1 regularization for linear regression
L1 규제 $\alpha\left \| \mathbf{w} \right \|_{1}$를 cost function에 더합니다.
$\tilde{\jmath(\mathbf{w})} = MSE_{train} + \alpha\left \| \mathbf{w} \right \|_{1}
= \frac{1}{n} \left \| \mathbf{X}\mathbf{w} - \mathbf{y} \right \|^{2} + \alpha\left \| \mathbf{w} \right \|_{1}$
규제를 더하는 것은 (과대적합이 되지 않도록 모델을 강제로 제한하는 것) 훈련 데이터를 잘 예측하기 위해서 뿐만 아니라 모든 특성이 출력에 주는 영향을 최소한으로 만들어줍니다.
원하는 만큼 모델을 규제하기 위하여 하이퍼파라미터 $\alpha$를 조정합니다.
만약 $\alpha$가 0이라면 규제된 선형 회귀 (릿지나 라쏘)는 단순히 회귀 분석으로 만든 모델과 같습니다.
만약 $\alpha$가 매우 크면, 모든 파라미터는 결국 0과 매우 가깝게 됩니다. 결과로 평평한 선은 트레이닝 셋의 레이블의 평균을 통과하게 됩니다.
import mglearn
X, y = mglearn.datasets.load_extended_boston()
print(X.shape, y.shape)
보스턴 주택가격 데이터셋에 어떻게 적용되는지 살펴보겠습니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
훈련 데이터셋과 테스트 데이터셋으로 나눠줍니다.
from sklearn.linear_model import Ridge
reg = Ridge(alpha = 1)
reg.fit(X_train, y_train)
Ridge을 임포트하고 객체를 만듭니다. 하이퍼파라미터 $\alpha$는 1로 설정헀습니다.
훈련 세트를 사용하여 모델을 학습시킵니다.
y_train_hat = reg.predict(X_train)
print('MAE :', mean_absolute_error(y_train, y_train_hat))
print('RMSE :', mean_squared_error(y_train, y_train_hat)**0.5)
print('R_square :', r2_score(y_train, y_train_hat))
y_test_hat = reg.predict(X_test)
print('MAE :', mean_absolute_error(y_test, y_test_hat))
print('RMSE :', mean_squared_error(y_test, y_test_hat)**0.5)
print('R_square :', r2_score(y_test, y_test_hat))
훈련 세트에서의 점수는 LinearRegression보다 낮지만 테스트 세트에 대한 점수는 더 높습니다.
선형 회귀는 이 데이터셋에 과대적합되지만 Ridge는 덜 자유로운 모델이기 때문에 과대적합이 적어집니다.
모델의 복잡도가 낮아지면 훈련 세트에서의 성능은 나빠지지만 더 일반화된 모델이 됩니다.
관심이 있는 것은 테스트 세트에 대한 성능이기 때문에 LinearRegression보다 Ridge 모델을 선택해야합니다.
training_r2 = []
test_r2 = []
alpha_settings = [0, 0.1, 1, 10]
for alpha in alpha_settings:
#bulid the model
reg = Ridge(alpha = alpha)
reg.fit(X_train, y_train)
# r2 on the training set
y_train_hat = reg.predict(X_train)
training_r2.append(r2_score(y_train, y_train_hat))
# r2 on the test set
y_test_hat = reg.predict(X_test)
test_r2.append(r2_score(y_test, y_test_hat))
하이퍼파라미터 $\alpha$를 다르게 해보고 성능을 평가했습니다.
r2_data = pd.DataFrame({'alpha' : alpha_settings,
'training_r2' : training_r2,
'test_r2' : test_r2})
r2_data
최적의 alpha 값은 사용하는 데이터셋에 달렸습니다.
alpha 값을 높이면 계수를 0에 더 가깝게 만들어서 훈련 세트의 성능은 나빠지지만 일반화에는 도움을 줄 수 있습니다.
이 코드에서 alpha=0.1이 꽤 좋은 성능을 낸 것 같습니다.
테스트 세트에 대한 성능이 높아질 때까지 alpha 값을 줄일 수 있을 것입니다.
from sklearn.linear_model import Ridge
lr = LinearRegression().fit(X_train, y_train)
ridge = Ridge().fit(X_train, y_train)
ridge10 = Ridge(alpha=10).fit(X_train, y_train)
ridge01 = Ridge(alpha=0.1).fit(X_train, y_train)
plt.plot(ridge.coef_, 's', label="Ridge alpha=1")
plt.plot(ridge10.coef_, '^', label="Ridge alpha=10")
plt.plot(ridge01.coef_, 'v', label="Ridge alpha=0.1")
plt.plot(lr.coef_, 'o', label="LinearRegression")
plt.xlabel("Coefficient index")
plt.ylabel("Coefficient magnitude")
xlims = plt.xlim()
plt.hlines(0, xlims[0], xlims[1])
plt.xlim(xlims)
plt.ylim(-25, 25)
plt.legend()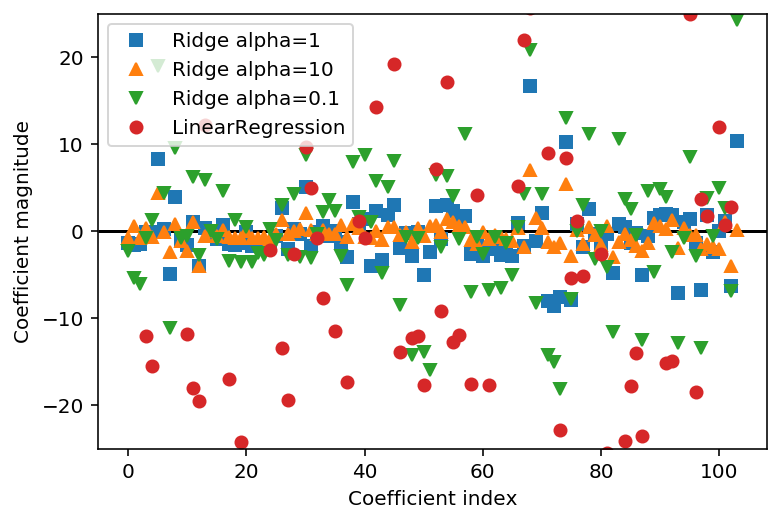
선형 회귀와 몇 가지 alpha 값을 가진 릿지 회귀의 계수 크기를 비교해보겠습니다.
alpha=10일 때 대부분의 계수는 -3과 3사이에 위치합니다.
alpha=1일 때 릿지 모델의 계수는 좀 더 커졌습니다.
alpha=0.1일 때 계수는 더 커지며 아무런 규제가 없는 선형 회귀의 계수는 값이 더 커져 그림 밖으로 넘어갑니다.
선형 회귀 규제 - 라쏘
import mglearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Lasso
from sklearn.metrics import r2_score
X, y = mglearn.datasets.load_extended_boston()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
Ridge의 대안으로 Lasso가 있습니다.
확장된 보스턴 주택가격 데이터셋에 라쏘를 적용해보겠습니다.
num_vars = []
training_r2 = []
test_r2 = []
alpha_settings = [0, 0.0001, 0.01, 1]
for alpha in alpha_settings:
#bulid the model
reg = Lasso(alpha = alpha)
reg.fit(X_train, y_train)
num_vars.append(sum(reg.coef_ != 0))
# r2 on the training set
y_train_hat = reg.predict(X_train)
training_r2.append(r2_score(y_train, y_train_hat))
# r2 on the test set (generalization)
y_test_hat = reg.predict(X_test)
test_r2.append(r2_score(y_test, y_test_hat))r2_data = pd.DataFrame({'alpha' : alpha_settings,
'n.variables used' : num_vars,
'training_r2' : training_r2,
'test_r2' : test_r2})
r2_data
alpha=1.0일 때 훈련 세트와 테스트 세트 모두에서 결과가 좋지 않습니다. 과소적합입니다.
과소적합을 줄이기 위해서 alpha값을 줄여보았습니다.
alpha 값을 낮추면 모델의 복잡도는 증가하여 훈련 세트와 테스트 세트에서의 성능이 좋아집니다.
성능은 Ridge보다 조금 나은데 사용된 특성은 104개 중 33개뿐이어서, 아마도 모델을 분석하기가 조금 더 쉽습니다.
그러나 alphar 값을 너무 낮추면 규제의 효과가 없어져 과대적합이 되므로 LinearRegression의 결과가 비슷해집니다.
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
lasso001 = Lasso(alpha=0.01, max_iter=100000).fit(X_train, y_train)
lasso00001 = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)
plt.plot(lasso.coef_, 's', label="Lasso alpha=1")
plt.plot(lasso001.coef_, '^', label="Lasso alpha=0.01")
plt.plot(lasso00001.coef_, 'v', label="Lasso alpha=0.0001")
plt.plot(ridge01.coef_, 'o', label="Ridge alpha=0.1")
plt.legend(ncol=2, loc=(0, 1.05))
plt.ylim(-25, 25)
plt.xlabel("Coefficient index")
plt.ylabel("Coefficient magnitude")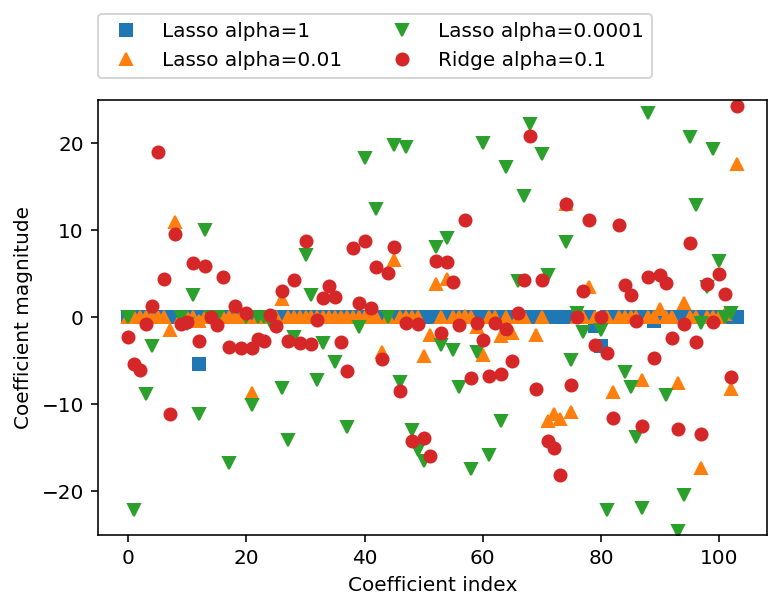
L1 규제의 결과로 라쏘를 사용할 때 어떤 계수는 정말 0이 됩니다.
이 말은 모델에서 완전히 제외되는 특성이 생긴다는 뜻입니다.
어떻게 보면 특성 선택이 자동으로 이뤄진다고 볼 수 있습니다. 일부 계수를 0으로 만들면 모델을 이해하기 쉬워지고 이 모델의 가장 중요한 특성이 무엇인지 드러내줍니다.
분류용 선형 모델
선형 모델은 분류에도 널리 사용합니다. 이진 분류를 살펴보겠습니다.
이진 선형 분류기는 선, 평면, 초평면을 사용해서 두 개의 클래스를 구분하는 분류기입니다.
분류형 선형 모델에서는 결정 경계가 입력의 선형 함수입니다.
로지스틱 회귀
Logistic Regression
출력 변수가 이진인 상황으로 선형 회귀의 아이디어를 확장합니다. (y = 0 or 1)
$\hat{y} = \sigma(\mathbf{W^{T}}\mathbf{x}) = \frac{1}{1 + exp(-\mathbf{w^{T}}\mathbf{x})} $
$\mathbf{x} = (x^{1}, ..., x^{d}) \in R^{d}, \hat{y} \in [0, 1]$
만약 $\hat{y} > 0.5$이면, "1"로 분류하고 $\hat{y} < 0.5$이면, "0"으로 분류합니다.

훈련 데이터 셋
$D = \left \{ (\mathbf{x_{1}}, y_{1}), (\mathbf{x_{2}}, y_{2}), ..., (\mathbf{x_{n}}, y_{n}) \right \}$
$\mathbf{x_{i}} = (1, x_{i}^{1}, ..., x_{i}^{d}) \in R^{d+1}$는 입력 변수 d의 i번째 입력 벡터(vector)이고
$y_{i} \in \left \{ 0, 1 \right \}$는 대응하는 출력 변수의 레이블입니다.
선형 회귀의 출력 (y 예측)
$\hat{y} = f(\mathbf{x}) = \sigma(\mathbf{W^{T}}\mathbf{x}) = \frac{1}{1 + exp(-\mathbf{w^{T}}\mathbf{x})}, \hat{y} \in [0, 1]$
훈련 : training error를 최소화하는 최적의 파라미터 $\mathbf{w}^{*}$를 찾습니다. (cost function)
여기서는 "cross-entropy" loss를 사용합니다.
$\jmath(\mathbf{w}) = \frac{1}{n} \sum_{(\mathbf{x_{i}},y_{i}) \in D} L(y_{I}, \hat{y}_{i}) = \frac{1}{n} \sum_{(\mathbf{x_{i}},y_{i}) \in D} [-y_{i} log \hat{y}_{i} - (1 - y_{i})log(1 - \hat{y}_{i})]$
어떻게 찾을 수 있을까요? 경사하강법 (gradient descent)을 이용합니다. (no closed-from solution)
수렴할 때까지 다음을 반복합니다.
$\mathbf{w} := \mathbf{w} - \epsilon\triangledown_{\mathbf{w}}\jmath(\mathbf{w})$
$-> w_{j} := w_{j} - \epsilon\frac{\partial }{\partial w_{j}}\jmath(\mathbf{w}), \forall w_{j} \in \mathbf{w}$
$\epsilon$은 learning rate입니다.

훈련 모델 $f(\mathbf{x}) = \sigma(\mathbf{w}^{*T}\mathbf{x})$
로지스틱 회귀 유도
$\mathbf{{\theta}} := \mathbf{\theta} - \epsilon\triangledown_{\mathbf{\theta}}\jmath(\mathbf{\theta})$는 어디서부터 유도되었을까요?
미적분의 테일러 급수를 상기합니다.
Taylor expansion of a function of $\mathbf{\theta}$
$\jmath(\mathbf{\theta}) = \jmath(\mathbf{\theta_{0}}) + (\mathbf{\theta} - \mathbf{\theta_{0}})^{T}\triangledown_{\mathbf{\theta}}\jmath(\mathbf{\theta_{0}}) + \frac{1}{2}(\mathbf{\theta} - \mathbf{\theta_{0}})^{T}\triangledown_{\mathbf{\theta}}^{2}\jmath(\mathbf{\theta_{0}})(\mathbf{\theta} - \mathbf{\theta_{0}}) + ...$
First-order approximation (assume that $\mathbf{\theta}$ is very close to $\mathbf{\theta_{0}}$
$\jmath(\mathbf{\theta}) \simeq \jmath(\mathbf{\theta_{0}}) + (\mathbf{\theta} - \mathbf{\theta_{0}})^{T}\triangledown_{\mathbf{\theta}}\jmath(\mathbf{\theta_{0}})$
We want to find a direction $\mathbf{\theta_{0}}$ -> $\mathbf{\theta}$ to make $\imath(\mathbf{\theta}) < \imath(\mathbf{\theta_{0}})$
$\imath(\mathbf{\theta}) - \imath(\mathbf{\theta_{0}}) \simeq (\mathbf{\theta} - \mathbf{\theta_{0}})^{T}\triangledown_{\mathbf{\theta}}\jmath(\mathbf{\theta_{0}}) < 0$
The best direction
$\triangledown_{\mathbf{\theta}}\jmath(\mathbf{\theta_{0}}) \propto - (\mathbf{\theta} - \mathbf{\theta_{0}})$
$\triangledown_{\mathbf{\theta}}\jmath(\mathbf{\theta_{0}}) = -\epsilon (\mathbf{\theta} - \mathbf{\theta_{0}}), \epsilon > 0$
$\mathbf{\theta} = \mathbf{\theta_{0}} - \epsilon \triangledown_{\mathbf{\theta}}\jmath(\mathbf{\theta_{0}}), \epsilon > 0$

First-Order Approximation을 기반으로한 Optimization의 예를 묘사했습니다.
$L(y, \hat{y}) = -ylog\sigma(z) - (1 - y)log(1 - \sigma(z)),$
$where ~\hat{y} = \sigma(z), z = \mathbf{w^{T}}\mathbf{x} = w_{0} + w_{1}x^{1} + ... + w_{d}x^{d}$
$\frac{\partial L(\mathbf{w})}{\partial w_{j}} = \frac{\partial L(\mathbf{w})}{\partial z}\frac{\partial z}{\partial w_{j}} = (\hat{y} - y)x^{j}$
$\frac{\partial L(\mathbf{w})}{\partial z} = -y\frac{\partial log\sigma(z)}{\partial z} - (1 = y)\frac{\partial log(1 - \sigma(z))}{\partial z}$
$= -y\frac{1}{\sigma(z)}\frac{\partial \sigma(z)}{\partial z} - (1 - y)\frac{-1}{1 - \sigma(z)}\frac{\partial \sigma(z)}{\partial z}$
$=-y\frac{1}{\sigma(z)}\sigma(z)(1 - \sigma(z)) - (1 - y)\frac{-1}{1 - \sigma(z)}\sigma(z)(1 - \sigma(z))$
$= -y + \sigma(z) = \hat{y} - y $
$\frac{\partial z}{\partial w_{j}} = \frac{\partial (w_{0} + w_{1}x^{1} + ... + w_{d}x^{d})}{\partial w_{j}} = x^{j}$
로지스틱 회귀 예시 - forge 데이터셋
LogisticRegression에서 규제의 강도를 결정하는 하이퍼파라미터는 C입니다.
C 값이 높아지면 규제가 감소합니다.
L2 규제를 디폴트 값으로 사용합니다.
import mglearn
X, y = mglearn.datasets.make_forge()
foge 데이터셋을 사용합니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
훈련 세트와 테스트 세트로 나눕니다.
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X_train, y_train)
LogisticRegression 모델을 만듭니다.
y_test_hat = clf.predict(X_test)
print(y_test)
print(y_test_hat)
실제 y와 예측한 y를 나타냈습니다.
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_test_hat))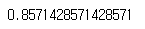
정확도를 계산했습니다.
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
X, y = mglearn.datasets.make_forge()
fig, axes = plt.subplots(1, 2, figsize=(10, 3))
for model, ax in zip([LinearSVC(), LogisticRegression()], axes):
clf = model.fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=False, eps=0.5,
ax=ax, alpha=.7)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title(clf.__class__.__name__)
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")
axes[0].legend()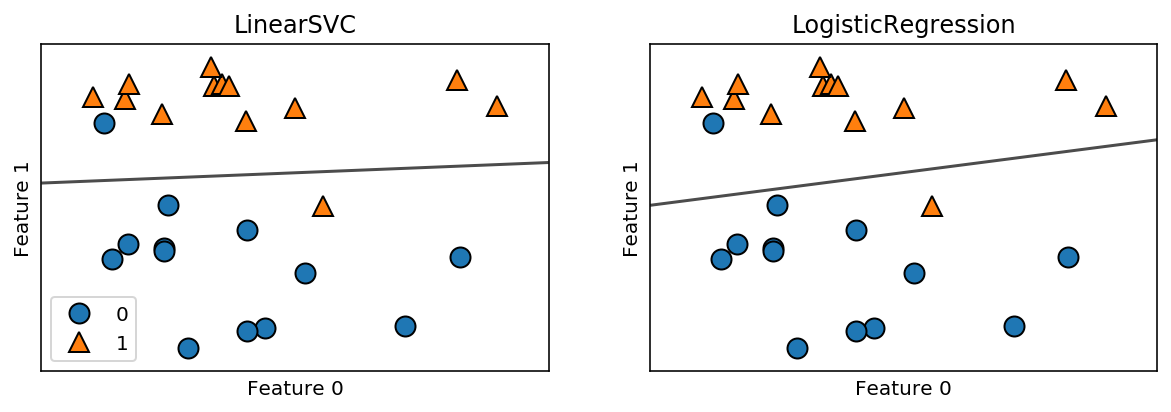
오른쪽 그림이 로지스틱 회귀 모델의 결정 경계입니다.
로지스틱 회귀 예시 - 유방암 데이터셋
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=42)training_accuracy = []
test_accuracy = []
C_settings = [0.001, 0.01, 0.1, 1, 10, 100]
for C in C_settings:
#bulid the model
clf = LogisticRegression(C=C)
clf.fit(X_train, y_train)
# accuracy on the training set
y_train_hat = clf.predict(X_train)
training_accuracy.append(accuracy_score(y_train, y_train_hat))
# accuracy on the training set
y_test_hat = clf.predict(X_test)
test_accuracy.append(accuracy_score(y_test, y_test_hat))
유방암 데이터셋을 사용했습니다.
C 값을 다르게 해주고 성능을 평가했습니다.
C_data = pd.DataFrame({'C' : C_settings,
'training accuarcy' : training_accuracy,
'test accuarcy' : test_accuracy})
C_data
C의 값이 낮아지면 데이터 포인트 중 다수에 맞추려고 하고, C의 값을 높이면 개개의 데이터 포인트를 정확히 분류하려고 노력합니다.
기본값 C=1이 훈련 세트와 테스트 세트 양쪽에 95%의 정확도로 꽤 훌륭한 성능을 내고 있습니다.
그러나 훈련 세트와 테스트 세트의 성능이 매우 비슷하므로 과소적합인 것 같습니다.
C=100을 사용하니 훈련 세트의 정확도가 높아졌고, 테스트 세트의 정확도도 조금 증가했습니다.
이는 복잡도가 높은 모델일수록 성능이 좋음을 말해줍니다.
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=42)
logreg = LogisticRegression().fit(X_train, y_train)
logreg100 = LogisticRegression(C=100).fit(X_train, y_train)
logreg001 = LogisticRegression(C=0.01).fit(X_train, y_train)
plt.plot(logreg.coef_.T, 'o', label="C=1")
plt.plot(logreg100.coef_.T, '^', label="C=100")
plt.plot(logreg001.coef_.T, 'v', label="C=0.001")
plt.xticks(range(cancer.data.shape[1]), cancer.feature_names, rotation=90)
xlims = plt.xlim()
plt.hlines(0, xlims[0], xlims[1])
plt.xlim(xlims)
plt.ylim(-5, 5)
plt.xlabel("Feature")
plt.ylabel("Coefficient magnitude")
plt.legend()
C 설정을 세 가지로 다르게 하여 학습시킨 모델의 계수는 위와 같습니다.
다중 클래스 분류용 선형 모델
많은 선형 분류 모델은 태생적으로 이진 분류만을 지원합니다. 즉 다중 클래스를 지원하지 않습니다.
이진 분류 알고리즘을 다중 클래스 분류 알고리즘으로 확장하는 보편적인 기법은 일대다 방법입니다.
일대다 방식은 각 클래스를 다른 모든 클래스와 구분하도록 이진 분류 모델을 학습시킵니다.
결국 클래스 수만큼 이진 분류 모델이 만들어집니다. 예측을 할 때 이렇게 만들어진 모든 이진 분류기가 작동하여 가장 높은 점수를 내는 분류기의 클래스를 예측값으로 선택합니다.
세 개의 클레스를 가진 간단한 데이터셋에 일대다 방식을 적용해보겠습니다.
from sklearn.datasets import make_blobs
X, y = make_blobs(random_state=42)
blobs 데이터셋을 사용합니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
훈련 데이터셋과 테스트 데이터셋으로 나눕니다.
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X_train, y_train)
분류기를 훈련시킵니다.
y_test_hat = clf.predict(X_test)
print(y_test_hat)
예측 결과입니다.
from sklearn.datasets import make_blobs
from sklearn.svm import LinearSVC
X, y = make_blobs(random_state=42)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.legend(["Class 0", "Class 1", "Class 2"])
linear_svm = LinearSVC().fit(X, y)
print("Coefficient shape: ", linear_svm.coef_.shape)
print("Intercept shape: ", linear_svm.intercept_.shape)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
line = np.linspace(-15, 15)
for coef, intercept, color in zip(linear_svm.coef_, linear_svm.intercept_,
mglearn.cm3.colors):
plt.plot(line, -(line * coef[0] + intercept) / coef[1], c=color)
plt.ylim(-10, 15)
plt.xlim(-10, 8)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.legend(['Class 0', 'Class 1', 'Class 2', 'Line class 0', 'Line class 1',
'Line class 2'], loc=(1.01, 0.3))
세 개의 일대다 분류기가 만든 결정 경계입니다.
결론
선형 모델의 주요 하이퍼파라미터
규제의 타입 (L1 vs L2)
규제 하이퍼파라미터 alpha (or C)
평가 데이터셋에서 가장 높은 성능이 나온것을 택합니다.
데이터를 미리 전처리해놓는 것이 중요합니다. (data scaling and one-hot encoding)
장점
학습속도가 빠르고 예측도 빠릅니다.
매우 큰 데이터셋과 희소한 데이터셋에도 잘 작동합니다.
공식을 사용해 예측이 어떻게 만들어지는지 비교적 쉽게 이해할 수 있습니다.
샘플에 비해 특성이 많을 때 잘 작동합니다.
단점
데이터셋의 특성들이 서로 깊게 연관되어 있을 때 계수의 값들이 왜 그런지 명확하지 않을 때가 종종 있습니다.
입출력 변수가 비선형관계일 때 성능이 좋지 못합니다.
L1 규제 or L2 규제를 결정하는 경우
L1을 사용한다면
중요한 특성이 많이 않다고 생각하면 L1 규제를 사용합니다.
모델의 해석이 중요한 요소일 때도 사용합니다.
L2를 사용한다면
기본적으로 L2 규제를 사용합니다.
파이썬 라이브러리를 활용한 머신러닝 책과 성균관대학교 강석호 교수님 수업 내용을 바탕으로 요약 작성되었습니다.
'파이썬 라이브러리를 활용한 머신러닝' 카테고리의 다른 글
| Uncertainty Estimates from Classifiers & Summary and Outlook (0) | 2019.11.15 |
|---|---|
| Neural Networks (0) | 2019.11.14 |
| Support Vector Machines (0) | 2019.11.13 |
| Decision Trees (0) | 2019.11.12 |
| K-Nearest Neighbors (0) | 2019.11.08 |




댓글