K-최근접 이웃 알고리즘(k-Nearst Neighbors)
K-NN 모델은 단순히 훈련 데이터를 저장하여 만들어집니다.
새로운 데이터 포인트에 대한 예측이 필요하면 알고리즘은 새 데이터 포인트에서 가장 가까운 훈련 데이터 포인트를 찾습니다. 즉, '최근접 이웃'을 찾습니다.
찾은 훈련 데이터의 레이블을 새 데이터 포인트의 레이블로 지정합니다.
트레이닝 데이터셋 $D = \left \{(\mathbf{x_{1}}, y_{1}), (\mathbf{x_{2}}, y_{2}), ..., (\mathbf{x_{n}}, y_{n}) \right \}$
$\mathbf{x_{i}} = (x_{i}^{1}, ..., x_{i}^{d}) \in R^{d}$는 입력 변수 d의 i번째 입력 벡터(vector)이고
$y_{i}$는 대응하는 출력 변수의 레이블입니다.
테스트 데이터의 새로운 점 $\mathbf{x_{new}}$의 예측은 다음과 같습니다.
1. $\mathbf{x_{new}}$로부터 $D$ 안의 각 데이터 포인트의 거리를 계산합니다. (distance metric)
2. $\mathbf{x_{new}}$의 k 최근접 이웃을 확인합니다. $kNN(\mathbf{x_{new}}) = \left \{(\mathbf{x_{1}}, y_{1}), (\mathbf{x_{2}}, y_{2}), ..., (\mathbf{x_{n}}, y_{n}) \right \} \sqsubset D_{(k)} $
3. $\hat{y_{new}}$ 예측한 최근접 이웃의 레이블을 사용합니다. (weighting scheme)
분류, 회귀 레이블 정하는 방법
분류의 경우
$voting : \hat{y} = \underset{j}{argmax}\sum_{(\mathbf{x_{(i)}},y{(i)}) \in kNN(\mathbf{x})}I(y_{(i)}=j)$
$Weighted Voting : voting : \hat{y} = \underset{j}{argmax}\sum_{(\mathbf{x_{(i)}},y{(i)}) \in kNN(\mathbf{x})}w(\mathbf{x_{(i)}}, \mathbf{x})I(y_{(i)}=j)$
회귀의 경우
$Averaging : \hat{y} = \frac{1}{k}\sum_{(\mathbf{x_{(i)}},y{(i)}) \in kNN(\mathbf{x})}y_{(i)}$
$Weighted Averaging : \hat{y} = \frac{1}{k}\sum_{(\mathbf{x_{(i)}},y{(i)}) \in kNN(\mathbf{x})} w(\mathbf{x_{(i)}}, \mathbf{x})y_{(i)}$
$w(\mathbf{x_{(i)}}, \mathbf{x})$는 가중치함수입니다(하이퍼파라미터(hyperparameter), 학습되지 않음)
예를 들어, inverse of Euclidean distance $\frac{1}{\left \| x_{i} - x \right \|}_{2}$
하이퍼파라미터
최근접 이웃 k의 숫자
이웃을 적게 사용하면 모델의 복잡도는 높아집니다.
이웃을 많이 사용하면 모델의 복잡도는 낮아집니다.
거리 측정(Distance metric)
Euclidean : ${\left \| x_{i} - x \right \|}_{2}$, sqrt(sum((x-y)^2))
Manhattan : ${\left \| x_{i} - x \right \|}_{1}$, sum( | x - y | )
Minkowski: ${\left \| x_{i} - x \right \|}_{k}$, sum( | x - y |^p)^(1/p)
가중치 함수(Weight Functions)
Uniform : $w(\mathbf{x_{(i)}}, \mathbf{x}) = 1 $
Distance Weight (Inverse of Euclidean) : $w(\mathbf{x_{(i)}}, \mathbf{x}) = \frac{1}{\left \| x_{i} - x \right \|}_{2}$
Distance Weight (Inverse of Manhattan) : $w(\mathbf{x_{(i)}}, \mathbf{x}) = \frac{1}{\left \| x_{i} - x \right \|}_{1}$
Distance Weight (Inverse of Distance (p)) : $w(\mathbf{x_{(i)}}, \mathbf{x}) = \frac{1}{\left \| x_{i} - x \right \|}_{p}$
KNeighborsClassifier 분석 - 예제에 사용할 데이터셋
두 개의 특성을 가진 forge 데이터셋은 인위적으로 만든 이진 분류 데이터셋입니다.
# generate dataset
X, y = mglearn.datasets.make_forge()
# plot dataset
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.legend(["Class 0", "Class 1"], loc=4)
plt.xlabel("First feature")
plt.ylabel("Second feature")
print("X.shape:", X.shape)
데이터를 DataFrame으로 보여주겠습니다,.
data = pd.DataFrame({'y' : y,
'X0' : X[:, 0],
'X1' : X[:, 1]})
data
KNeighborsClassifier 분석 - k=3
import mglearn
X, y = mglearn.datasets.make_forge()
Forge 데이터셋을 만들어줍니다.
from sklearn.model_selection import train_test_split
X_test, X_train, y_test, y_train = train_test_split(X, y, test_size = 0.25, random_state=0)
데이터를 훈련 세트와 테스트 세트로 나눕니다.
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(X_train, y_train)
KNeighborsClassifier를 임포트하고 객체를 만듭니다. 이웃의 수를 3으로 지정합니다.
훈련 세트를 사용하여 분류 모델을 학습시킵니다.
KNeighborsClassifier에서의 학습은 예측할 때 이웃을 찾을 수 있도록 데이터를 저장하는 것입니다.
y_test_hat = clf.predict(X_test)
print(y_test)
print(y_test_hat)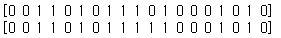
테스트 데이터에 대해 predict 매서드를 호출해서 예측합니다.
테스트 세트의 각 데이터 포인트에 대해 훈련 세트에서 가장 가까운 이웃을 계산한 다음 가장 많은 클래스를 찾습니다.
실제 테스트 세트와 예측 세트를 출력했습니다.
from sklearn.metrics import accuracy_score
y_train_hat = clf.predict(X_train)
print('train accuracy :', accuracy_score(y_train, y_train_hat))
y_test_hat = clf.predict(X_test)
print('test accuracy :', accuracy_score(y_test, y_test_hat))
모델이 얼마나 잘 일반화되었는지 평가하기 위해 accuracy_score 메서드를 사용하였습니다.
트레이닝 데이터의 정확도는 100%
테스트 데이터의 정확도는 94.73%로 나왔습니다.
즉 모델이 테스트 데이터셋에 있는 샘플 중 94.73%를 정확히 예측하였습니다.
Forge 데이터셋에 대한 3-최근접 이웃 모델의 예측을 그림으로 나타내겠습니다.
mglearn.plots.plot_knn_classification(n_neighbors=3)
Forge 데이터셋에 대한 1-최근접 이웃 모델의 예측을 그림입니다,
mglearn.plots.plot_knn_classification(n_neighbors=1)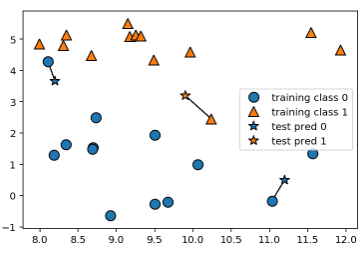
왼쪽 위의 것은 예측이 달라진 것을 알 수 있습니다.
하이퍼파라미터 k(n_neighbors)의 효과
알고리즘의 결정 경계를 그리겠습니다.
ig, axes = plt.subplots(1, 3, figsize=(10, 3))
for n_neighbors, ax in zip([1, 3, 9], axes):
# the fit method returns the object self, so we can instantiate
# and fit in one line
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{} neighbor(s)".format(n_neighbors))
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
axes[0].legend(loc=3)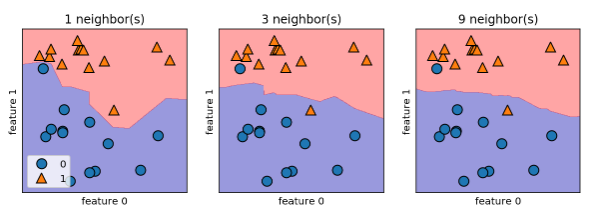
이웃을 하나 선택했을 때는 결정 경계가 훈련 데이터에 가깝게 따라ㄱ가고 있습니다.
이웃의 수를 늘릴수록 결정 경계는 더 부드러워집니다. 부드러운 경계는 더 단순한 모델을 의미합니다.
유방암 데이터 분석 - 이웃의 수 변화
데이터셋은 569개의 데이터 포인트와 30개의 입력 변수를 포함하고 있습니다.
각 데이터 포인트는 "benign" 또는 "malignant"로 레이블됩니다(이진 분류)
569개의 데이터 포인트는 212개는 malignant로 357개는 benign로 레이블되어있습니다.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=66)training_accuracy = []
test_accuracy = []
# try n_neighbors from 1 to 10
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
# build the model
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
# record training set accuracy
training_accuracy.append(clf.score(X_train, y_train))
# record generalization accuracy
test_accuracy.append(clf.score(X_test, y_test))
훈련 세트와 테스트 세트로 나눈 후 이웃의 수를 달리하여 훈련 세트와 테스트 세트의 성능을 평가합니다.
k_data = pd.DataFrame({'k' : neighbors_settings,
'training accuracy' : training_accuracy,
'test accuracy' : test_accuracy})
k_data
결과를 DataFrame으로 정리했습니다.
그림으로 나타내면
plt.plot(neighbors_settings, training_accuracy, label="training accuracy")
plt.plot(neighbors_settings, test_accuracy, label="test accuracy", )
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
최근접 이웃의 수가 하나일 떄는 훈련 데이터에 대한 예측이 완벽합니다.
이웃의 수가 늘어나면 모델은 단순해지고 훈련 데이터의 정확도를 줄어듭니다.
이웃을 하나 사용한 테스트 세트의 정확도는 이웃을 많이 사용했을 때보다 낮습니다.
이것은 1-최근접 이웃이 모델을 너무 복잡하게 만든다는 것을 설명해줍니다. (overfitting)
반대로 이웃을 10개 사용했을 때는 모델이 너무 단순해서 정확도는 더 나빠집니다. (underfitting)
정확도가 가장 좋을 때는 중간 정도인 여섯 개를 사용한 경우입니다.
유방암 데이터 분석 - distance metirc 변화
유방암 데이터를 가지고 또 다른 하이퍼파라미터인 distance metric을 변화시켜보겠습니다.
training_accuracy = []
test_accuracy = []
# try minkowski p from 1 to 5
p_settings = range(1, 6) #
for p in p_settings:
# build the model
clf = KNeighborsClassifier(n_neighbors=5, metric='minkowski', p=p)
clf.fit(X_train, y_train)
# record training set accuracy
training_accuracy.append(clf.score(X_train, y_train))
# record generalization accuracy
test_accuracy.append(clf.score(X_test, y_test))
이웃의 수를 5개로 metric을 'minkowski'로 바꿔주고 p를 1~5로 설정했습니다.
결과를 DataFrame으로 나타냈습니다.
P_data = pd.DataFrame({'P' : p_settings,
'training accuracy' : training_accuracy,
'test accuracy' : test_accuracy})
P_data
kNeighborsREgressor 분석 - k=3
import mglearn
X, y = mglearn.datasets.make_wave(n_samples=40)
plt.plot(X, y, 'o')
plt.ylim(-3, 3)
plt.xlabel("Feature")
plt.ylabel("Target")
회귀 알고리즘 설명에는 wave 데이터셋을 사용했습니다.
wave 데이터셋은 입력 특성 하나와 모델링할 타깃 변수(또는 응답)를 가집니다.
데이터를 DataFrame으로 나타내보겠습니다.
차원 떄문에 DataFrame으로 나타낼 때만 차원을 조정해주겠습니다.
X_1 = X.reshape(40, )re_data = pd.DataFrame({'y' : y,
'X' : X_1})
re_data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
wave 데이터셋을 훈련 세트와 테스트 세트로 나눕니다.
from sklearn.neighbors import KNeighborsRegressor
reg = KNeighborsRegressor(n_neighbors=3)
reg.fit(X_train, y_train)
이웃의 수를 3으로 하여 모델의 객체를 만들고 훈련 데이터와 타깃을 이용하여 모델을 학습시킵니다.
y_test_hat = reg.predict(X_test)
print(y_test)
print(y_test_hat)
테스트 세트의 실제 y와 예측 y를 출력했습니다.
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
print('MAE :', mean_absolute_error(y_test, y_test_hat))
print('RMSE :', mean_squared_error(y_test, y_test_hat)**0.5)
print('R_square :', r2_score(y_test, y_test_hat))
MAE, RMSE, R_square를 계산해 모델을 평가했습니다.
R^2의 점수가 0.83이라 모델이 비교적 잘 들어맞은 것 같습니다.
Wave 데이터셋에 대한 3-최근접 이웃 모델의 예측을 그림으로 나타내겠습니다.
mglearn.plots.plot_knn_regression(n_neighbors=3)
Wave 데이터셋에 대한 1-최근접 이웃 모델의 예측을 그림으로 나타내겠습니다.
mglearn.plots.plot_knn_regression(n_neighbors=1)
하이퍼파라미터 k(n_neighbors)의 효과
1차원 데이터셋에 대해 가능한 모든 특성 값을 만들어 예측해볼 수 있스빈다.
n_neighbors 값에 따라 최근접 이웃 회귀로 만들어진 예측을 비교해보겠습니다.
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# create 1,000 data points, evenly spaced between -3 and 3
line = np.linspace(-3, 3, 1000).reshape(-1, 1)
for n_neighbors, ax in zip([1, 3, 9], axes):
# make predictions using 1, 3, or 9 neighbors
reg = KNeighborsRegressor(n_neighbors=n_neighbors)
reg.fit(X_train, y_train)
ax.plot(line, reg.predict(line))
ax.plot(X_train, y_train, '^', c=mglearn.cm2(0), markersize=8)
ax.plot(X_test, y_test, 'v', c=mglearn.cm2(1), markersize=8)
ax.set_title(
"{} neighbor(s)\n train score: {:.2f} test score: {:.2f}".format(
n_neighbors, reg.score(X_train, y_train),
reg.score(X_test, y_test)))
ax.set_xlabel("Feature")
ax.set_ylabel("Target")
axes[0].legend(["Model predictions", "Training data/target",
"Test data/target"], loc="best")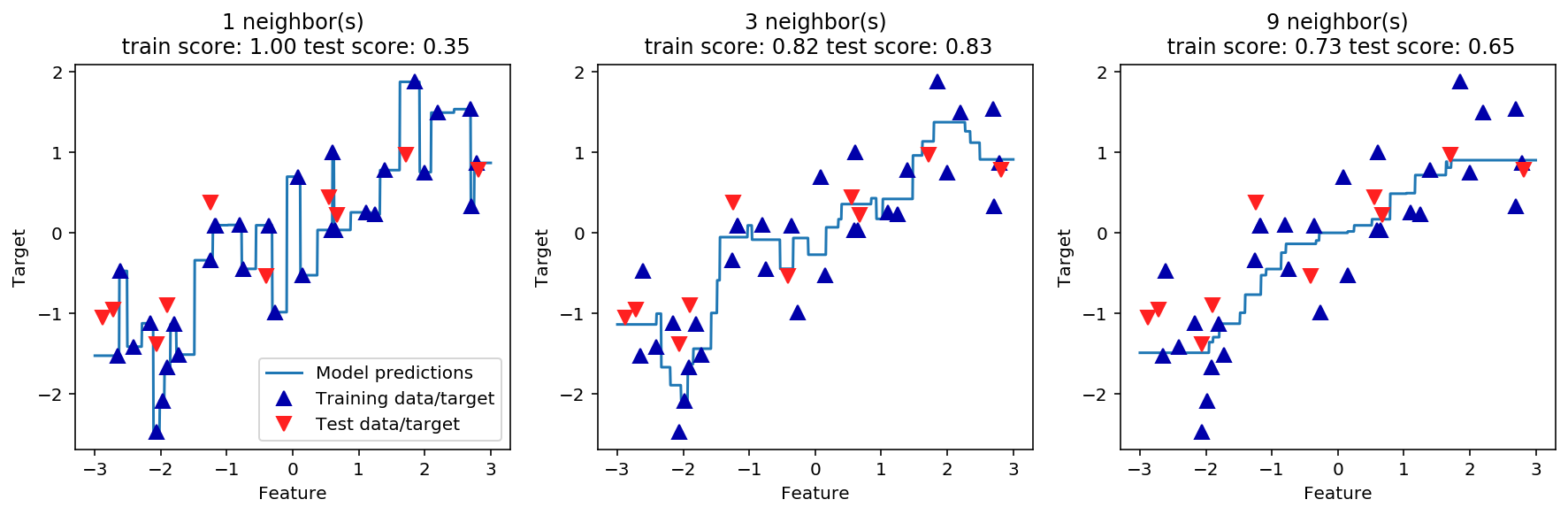
이웃을 하나만 사용하면 훈련 세트의 각 데이터 포인트가 예측에 주는 영향이 커서 예측값이 훈련 데이터 포인트를 모두 지나갑니다.
이는 매우 불안정한 예측을 만들어냅니다.
이웃을 많이 사용하면 잘 안 맞을 수 있지만 더 안정된 예측을 얻게 됩니다.
결론
k-NN 알고리즘의 중요한 하이퍼파라미터는 3개입니다.
이웃의 수(n_neighbor)
거리 재는 방법(metric)
가중치(weights)
실제로 이웃의 수는 3개나 5개 정도로 적을 때 잘 작동하지만 하이퍼파라미터를 잘 조정해야합니다.
일반적으로 평가 데이터셋에서 가장 높은 퍼포먼스를 보이는 것을 선택합니다.
데이터 정규화와 one-hot encoding등을 사용하여 데이터를 우선 정제하는 것이 매우 중요합니다.
장점
매우 쉬운 모델이고 많이 조정하지 않아도 자주 좋은 성능을 발휘합니다.
더 복잡한 알고리즘을 적용해보기 전에 시도해볼 수 있는 좋은 시작점입니다.
단점
훈련 세트가 매우 크면(특성의 수나 샘플의 수가 클 경우) 예측이 느려집니다.
k-NN 알고리즘을 사용할 떄는 데잍를 전처리하는 과정이 중요합니다.
(수백 개 이상의) 많은 특성을 가진 데이터 셋에는 잘 동작하지 않으며, 툭성 값 대부분이 0인 (즉 희소한) 데이터셋과는 특히 잘 작동하지 않습니다.
이러한 단점 때문에 현업에서는 선형 모델을 사용하고 있습니다.
파이썬 라이브러리를 활용한 머신러닝 책과 성균관대학교 강석호 교수님 수업 내용을 바탕으로 요약 작성되었습니다.
'파이썬 라이브러리를 활용한 머신러닝' 카테고리의 다른 글
| Uncertainty Estimates from Classifiers & Summary and Outlook (0) | 2019.11.15 |
|---|---|
| Neural Networks (0) | 2019.11.14 |
| Support Vector Machines (0) | 2019.11.13 |
| Decision Trees (0) | 2019.11.12 |
| Linear Models (2) | 2019.11.11 |




댓글