Resampling methods란 무엇인가요?
Resampling methods란 training data에서 반복적으로 sample들을 뽑고 적합한 모델에 대한 더 많은 정보를 얻기 위하여
각각의 샘플들을 모델에 재 적합시키는 방법입니다.
모델 평가 측면에서 test error rates를 추정한다든지
모델 선택 측면에서 모델 유연성의 적절 수준을 선택하는 경우에 사용됩니다.
계산 비용이 많이 들지만 현재는 powerful한 컴퓨터들이 많아서 수월하게 할 수 있습니다.
resampling 두 가지 방법
교차 검증 (Cross Validation)
부트스트래핑 (Bootstrapping)
일반적인 접근: The Validation Set
가장 낮은 test (not training) error rate를 보이는 a set of variables를 찾고 싶다고 가정합니다.
만일 많은 data set을 가지고 있으면, 랜덤 하게 데이터를 training과 validation(testing) parts로 나눔으로써
달성할 수 있습니다.
training part는 각각의 가능한 모델을 형성합니다. 즉, 변수들의 다른 조합들입니다.
그리고 가장 낮은 error rate를 보이는 모델을 선택합니다. (validation data에 적용된)

예시: Auto Data
mpg ~ horsepower를 예측하고 싶다고 가정합니다.
두 개의 모델이 있습니다.
mpg ~ horsepower
mpg ~ horsepower + $horspower^{2}$
어떤 모델이 가장 적합한가요?
랜덤하게 분리한 Auto data set
training data (196 obs.), validation data (196. obs)
training data set을 이용하여 두 모델에 적합시킵니다.
validation data set을 이용하여 두 모델을 평가합니다.
가장 낮은 validation(testing) MSE를 가진 모델을 택합니다.
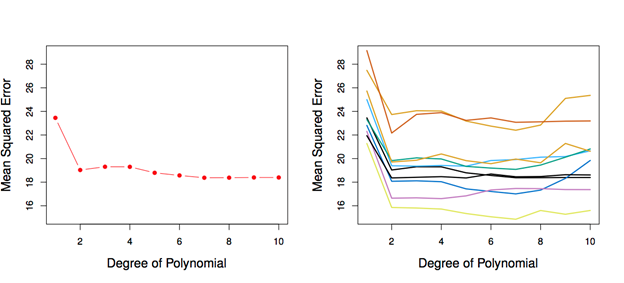
결과: Auto Data
왼쪽: Validation error rate for a single split
오른쪽: Validation method repeated 10 times, each time the split is done randomly
MSE 사이에 많은 변동들이 있습니다. 별로 좋지 않아 더 많은 안정된 모델이 필요합니다.
The Validation Set Approach
장점 :
간단하고 수행하기 쉽습니다.
단점 :
The validation MSE는 매우 가변적일 수 있습니다.
관측치의 부분집합만이 모델 적합에 사용됩니다. (training data) 적은 수의 관측치로 train 시 통계 방법의 성능이
떨어지는 경향이 있습니다.
'ISLR' 카테고리의 다른 글
| Ch05 Resampling Methods - k-fold Cross Validation (0) | 2019.09.30 |
|---|---|
| Ch05 Resampling Methods - Leave-One-Out Cross Validation(LOOCV) (0) | 2019.09.27 |
| Ch04 분류분석(3) - LDA & QDA (0) | 2019.09.25 |
| Ch04 분류분석(2) (0) | 2019.09.24 |
| Ch04 분류분석(1) (0) | 2019.09.23 |




댓글