데이터 set 만들기
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index=[4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index=[8, 9, 10, 11])df1

임의 이 데이터 set 3개를 만들어주고 한 개만 출력해줍니다.
DataFrame 형식으로 열 인덱스, 행 인덱스를 지정하여 데이터 set을 만들어줍니다.
나머지 데이터 set도 출력해주겠습니다.
df2
두 번째 데이터 셋을 출력합니다.
df3
세 번째 데이터 셋을 출력합니다.
데이터 set 병합하기 (아무 조건 없이)
result = pd.concat([df1, df2, df3])
result
concat 명령으로 데이터 셋을 병합합니다.
밑에 이어서 병합되는 모습을 볼 수 있습니다.
데이터 set 병합하기 (key 옵션 추가)
result = pd.concat([df1, df2, df3], keys=['x', 'y', 'z'])
result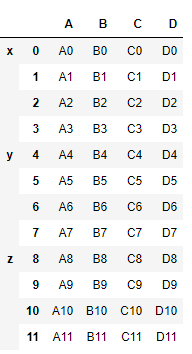
key 옵션을 이용하여 데이터 set 병합되는 전 자리에 인덱스를 더 추가해 줍니다.
key 옵션 자세히 살펴보기
result.index
병합된 데이터의 index를 살펴보면
앞에 병합하기 전 행 인덱스였던 숫자가 key index안에 속해 들어가 있는 것을 볼 수 있습니다.
result.index.get_level_values(0)
첫 번째 인덱스는 key의 x, y, z이고
result.index.get_level_values(1)
두 번째 인덱스는 초기에 설정했던 0, 1, 2,..., 11 임을 알 수 있습니다.
행, 열 인덱스 겹치는 set 생성 및 병합하기
df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
'D': ['D2', 'D3', 'D6', 'D7'],
'F': ['F2', 'F3', 'F6', 'F7']},
index=[2, 3, 6, 7])
result = pd.concat([df1, df4], axis=1)새로운 데이터 set df4를 생성합니다.
df1과 인덱스가 겹치는 것이 보입니다.
df1
df1을 다시 한 번 출력해주고
df4
df4를 살펴보면 행 인덱스 2,3이 열 인덱스 B와 F가 겹치는 것을 보실 수 있습니다.
내용 역시 겹치는 것도 있고 아닌 것도 있습니다.
이제 병합해주겠습니다.
result
df4가 열로 붙고 전체적으로 행과 열이 증가하였습니다. 양 쪽 데이터에서 해당되지 않은 부분은
NaN 표시가 떠있습니다.
데이터 병합 시 여러 가지 조건 시행하기
result = pd.concat([df1, df4], axis=1, join='inner')
result
axis = 1 옵션을 통해 열 인덱스 기준으로
join = 'inner' 옵션을 통해 겹치는 부분만 병합해줍니다.
axis = 0 옵션을 넣어주면 행 인덱스 기준으로 병합해 주게 됩니다.
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
result
join_axes = [df1.index] 옵션을 통해 df1의 인덱스를 사용하고
axis = 1이므로 행 인덱스를 기준으로 합니다.
result = pd.concat([df1, df4], ignore_index=True)
result

ignore_index = True 옵션을 넣어주면 데이터를 이어 붙이지 않고
겹치는 인덱스는 하나로 해서 병합해 주게 됩니다.
데이터를 병합하는 또 다른 방법 (merge 사용하기)
left = pd.DataFrame({'key': ['K0', 'K4', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
데이터를 새로 만들어주고
left
left 데이터는 이렇게 만들어 줬습니다.
right
right 데이터는 이렇습니다.
이제 데이터를 다른 방법으로 병합해 주겠습니다,
pd.merge(left, right, on='key')
merge 함수를 써서 left, right 데이터를 key가 겹치는 것끼리 병합해주었습니다.
pd.merge(left, right, how='left', on='key')
열 인덱스 key에 left 데이터 해당 열 부분을 기준으로 병합해줍니다.
right 데이터에는 C1 D1의 데이터는 없으므로 NaN이 뜹니다.
pd.merge(left, right, how='right', on='key')
이번에는 right 데이터를 기준으로 병합해 줍니다.
pd.merge(left, right, how='outer', on='key')
how = 'outer' 옵션을 넣어줬습니다.
key 인덱스가 전부 들어가 없는 내용은 NaN 처리가 됩니다.
pd.merge(left, right, how='inner', on='key')
how = 'inner' 옵션을 넣어주면
NaN에 해당하는 열이나 행을 없어지고 데이터가 완전히 차이는 부분만 병합되어 나타납니다.
나가며
Pandas 고급 단계로 데이터 병합하는 법을 배웠습니다.
많은 도움이 되셨으면 좋겠습니다. 감사합니다.
'Python > 라이브러리' 카테고리의 다른 글
| 편리한 시각화 도구 Seaborn (0) | 2019.09.19 |
|---|---|
| 파이썬의 대표 시각화 도구 Matplotlib (0) | 2019.09.17 |
| Pandas 기초 익히기 (0) | 2019.09.16 |



댓글