▶ pandas import
import pandas as pd
▶ csv 파일 불러오기
HOS_Seoul = pd.read_csv('10_to_18_number_hos.csv', encoding='utf-8')
HOS_Seoul.head()
csv 파일을 읽고 head 명령을 통해 앞 5줄만 불러왔습니다.
csv 파일을 읽을 때는 디렉터리가 같아야 한다는 점 반드시 명심하시길 바랍니다.
▶ 열 인덱스
HOS_Seoul.columns
열 인덱스로 기관명, 소계, ... 등이 있는 것을 확인합니다.
▶ 첫 번째 열 인덱스
HOS_Seoul.columns[0]
첫 번째 열 인덱스만 나타냅니다.
▶ 기관명을 구별로 바꾸기
HOS_Seoul.rename(columns={HOS_Seoul.columns[0] : '구별'}, inplace=True)
HOS_Seoul.head()
기관명으로 되어있던 첫번째 열 인덱스를 구별로 바꿔줍니다. inplace=True는 데이터에 변경사항을 적용합니다.
inplace=False라 되어있으면 그대로 기관명으로 결과가 나타납니다.
▶ 서울시 인구현황 파일 읽기
pop_Seoul = pd.read_excel('10_to_18_pop.xlsx', encoding='utf-8')
pop_Seoul.head()
수정을 하겠습니다. 저번 시간에 csv 형식으로 10_to_18_pop을 저장을 했는데 그렇게 되면 이다음 코드에서
데이터 형식 때문에 오류가 나게 됩니다. 따라서 csv가 아닌 xlsx로 바꿔주시길 바랍니다.
또한 2018년도만 필요하기에 그 전 데이터는 엑셀 내에서 수정해줬습니다.
사실 del을 써서 지워줘도 되나 파일을 다루는 방식을 알기 위해서 진행했습니다.
▶ 파일 수정하기
pop_Seoul = pd.read_excel('10_to_18_pop.xlsx',
header = 2,
usecols = 'B, D, G, J, P',
encoding='utf-8')
pop_Seoul.head()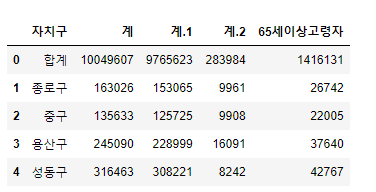
원래 파일에서는 인덱스도 두 번 나타나고 사용하지 않을 데이터들이 많습니다.
분석에 필요한 자치구, 총 합계, 한국인 합계, 등록 외국인 합계, 65세 이상 고령자만 남기겠습니다.
hearder = 2 두 번째 줄부터 불러와서 사용할 열들은 엑셀 기준으로 B, D, G, J, P입니다.
▶ 인덱스 한꺼번에 수정하기
pop_Seoul.rename(columns={pop_Seoul.columns[0] : '구별',
pop_Seoul.columns[1] : '인구수',
pop_Seoul.columns[2] : '한국인',
pop_Seoul.columns[3] : '외국인',
pop_Seoul.columns[4] : '고령자'}, inplace=True)
pop_Seoul.head()
자치구와 고령자 빼고는 어떤 인덱스인지 알 수가 없습니다. 병원 파일과 맞추고 알기 쉽게 바꿔주었습니다.
▶ 병원 데이터 head
HOS_Seoul.head()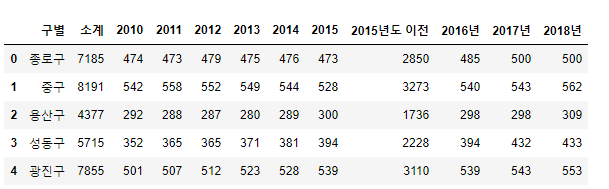
병원 데이터를 다시 불러옵니다. 병원 데이터에서 필요한 정보는 2015년도 이전, 2016년, 2017년, 2018년입니다.
수정하겠습니다. 다시 몇 줄만 불러오기 위해선 xlsx 형식이어야 합니다. 그러나 너무 번거로우므로
삭제해버리겠습니다.
▶ 불필요한 병원 데이터 열 삭제
del HOS_Seoul['2010']
del HOS_Seoul['2011']
del HOS_Seoul['2012']
del HOS_Seoul['2013']
del HOS_Seoul['2014']
del HOS_Seoul['2015']
HOS_Seoul.head()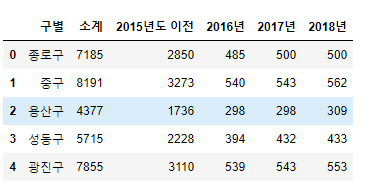
불 필요한 열 인덱스를 삭제하고 원하는 데이터만 남았습니다.
▶ 병원 데이터 소계 기준으로 오름차순 정렬하기
HOS_Seoul.sort_values(by='소계', ascending=True).head(5)
소계 인덱스를 기준으로 오름차순으로 정렬한 결과입니다.
by='(원하는 열 인덱스)', ascending=True(오름차순)입니다. False로 바꿔주면 내림차순이 됩니다.
병원 수가 가장 적은 구는 용산구, 금천구, 도봉구... 순입니다.
▶ 병원 데이터 소계 기준으로 내림차순 정렬하기
HOS_Seoul.sort_values(by='소계', ascending=False).head(5)
반대로 병원 수가 가장 많은 구는 강남구, 서초구, 송파구, 강동구... 순입니다.
강남 3구에 병원이 많고 특히 1위인 강남구와 2위인 서초구의 차이가 많이 난다는 점도 볼 수 있습니다.
▶ 최근 증가율 열 생성하기
HOS_Seoul['최근증가율'] = (HOS_Seoul['2016년'] + HOS_Seoul['2017년'] + \
HOS_Seoul['2018년']) / HOS_Seoul['2015년도 이전'] * 100
HOS_Seoul.sort_values(by='최근증가율', ascending=False).head(5)
최근 3년 간 병원수의 증가 비율이 높은 구는 순서대로 구로구, 강서구, 성동구... 순입니다.
여기서 에러가 뜨는 분들이 있습니다.
이는 엑셀 표시 형식이 일반으로 되어있어서 생긴 문제입니다,

엑셀 파일로 들어가셔서 오른쪽 위 표시 형식을 숫자로 바꿔준다음 소수점을 한자리만 나타내 줍니다(소수점은 안나타내 줘도 괜찮습니다).
저장하고 처음부터 코드를 다시 돌려보면 제대로 작동합니다.
▶ 인구 데이터 5줄 보여주기
pop_Seoul.head()
다시 인구 데이터로 돌아왔습니다.
▶ 합계 행 삭제하기
pop_Seoul.drop([0], inplace=True)
pop_Seoul.head()
구 별 데이터만 관심이 있으므로 총 합계는 삭제했습니다.
drop은 행을 삭제해 줍니다.
▶ 구별 인덱스 정렬해서 보여주기
pop_Seoul['구별'].unique()
구 인덱스만 array 정렬로 보여줍니다. unique는 겹치지 않는 것들로 보여줍니다.
▶ Null 값 확인하기
pop_Seoul[pop_Seoul['구별'].isnull()]
구별 열에 null값이 있는 지 확인합니다. 아무것도 뜨지 않으면 없는 것입니다.
▶ 외국인 비율과 고령자 비율 열 생성
pop_Seoul['외국인비율'] = pop_Seoul['외국인'] / pop_Seoul['인구수'] * 100
pop_Seoul['고령자비율'] = pop_Seoul['고령자'] / pop_Seoul['인구수'] * 100
pop_Seoul.head()
외국인 비율과 고령자 비율을 계산하고 새로운 열을 생성합니다.
▶ 인구수 열 기준으로 내림차순 정렬
pop_Seoul.sort_values(by='인구수', ascending=False).head(5)
인구수를 기준으로 내림차순 정렬해주었습니다. 송파구, 강서구, 노원구,... 순으로 인구가 많습니다.
▶ 외국인 열 기준으로 내림차순 정렬
pop_Seoul.sort_values(by='외국인', ascending=False).head(5)
외국인 열 기준으로 내림차순 정렬해주었습니다. 영등포구, 구로구, 금천구, 관악구, ...순으로 외국인이 많습니다.
pandas로 데이터를 불러오고 파악하고 처리를 조금 해줬습니다.
다음 시간에는 pandas로 전처리를 조금 더 해준 뒤에 그래프로 나타내보겠습니다.
'Python > 데이터 분석 예제' 카테고리의 다른 글
| 구글 맵스 API 이용 방법 (0) | 2019.10.01 |
|---|---|
| 서울시 구별 병원 현황 분석 - 데이터 병합 및 그래프 분석 (0) | 2019.09.26 |
| 서울시 구별 병원 현황 분석 - csv 데이터 변환하기 (0) | 2019.09.23 |
| 서울시 구별 병원 현황 분석 - 데이터 구하기 (0) | 2019.09.20 |




댓글