안녕하세요. 인문계공돌이입니다.
오늘은 G마켓 생수 데이터를 가지고 EDA를 진행하겠습니다.
EDA
EDA의 순서는 없습니다.
방법 또한 정해져 있는 것이 아니기 때문에 그때그때 생각나는 것을 해봤습니다.
예측을 하지 않고도 EDA만으로도 소중한 인사이트를 얻을 수 있습니다.

필요한 라이브러리를 불러왔습니다.
그래프에서 한글이 깨지지 않도록 했습니다.

G마켓 생수 데이터를 불러왔습니다.
가격에 쉼표로 천 단위가 구별되어 있었기 때문에 thousands=',' 옵션을 미리 추가했습니다.

연속형 변수의 기술통계량입니다.
가격의 최댓값은 66500원이고 최솟값은 4560원입니다.
4L부터 살 수 있으며 100L까지 판매하고 있습니다.

데이터의 크기입니다.
가격, 용량, 단위, 리터 모두 count가 639이니 이 변수들은 결측치가 없습니다.

변수 목록입니다.

다른 변수들 역시 639개의 관측치가 있습니다.

유니크한 값들을 보면 브랜드는 3개 즉, 제주삼다수, 스파클, 롯데칠성 아이시스입니다.
제품명에도 겹치는 것이 몇 개 있네요.
용량과 단위 역시 어느 정도 정해져 있습니다.
가격도 중복 값들이 많습니다.

데이터 타입을 보면 브랜드와 제품명은 범주형
가격, 용량, 단위, 리터는 연속형입니다.

한 번더 확인을 해도 그렇습니다.

결측치는 존재하지 않습니다.

가격 변수의 기술통계량을 좀 더 자세히 살펴봤습니다.
9900원이 가장 많습니다.

가격의 표준편차입니다.

가격의 왜도와 첨도입니다.
표본의 분포를 알아보기 위해 표준편차와 왜도, 첨도를 구했습니다.
좌측으로 치우쳐 있는 위로 솟은 모양을 하고 있습니다.
실제로 그런지 아래에서 시각화를 통해 보겠습니다.

1리터당 가격 비교를 위해 1리터당가격 변수를 추가해주었습니다.

1리터당가격 변수의 기술통계량입니다.

리터와 가격의 replot입니다.
리터가 클수록 가격이 높다고 가설을 세웠을 때 확인해 볼 수 있습니다.

각 브랜드별로도 리터가 클수록 가격이 높아지는 지 확인할 수 있습니다.
스파클이 제주삼다수보다는 리터가 커지는 것에 비해 가겨 상승이 그렇게 크지 않습니다.
롯데칠성 아이시스는 같은 리터에 가격대가 다양하게 분포하고 있습니다.

이런식으로 브랜드별로 스타일을 다양하게 줄 수 있습니다.

동그라미 사이즈별로 나타낼 수도 있지만 제주삼다수, 스파클, 롯데칠성 아이시스가 비교가 될 수 있기 때문에 좋지 않습니다.

1리터당가격을 보면 6000원 때문에 그래프가 한쪽으로 치우친 것처럼 보입니다.
주로 500~1500원 사이에 많이 분포되어 있습니다.

브랜드별로 보면 롯데칠성 아이시스가 수집이 많이 되었습니다.
그 다음 제주삼다수, 스파클 순입니다.

브랜드별로 1리터당 가격이 어떻게 분포되어 있는지 볼 수 있습니다.
스파클이 낮은 가격대를 형성하고 있습니다.
롯데칠성 아이시스는 다른 브랜드보다 좀 더 비싸게 팔리는 것도 있습니다.

윤곽만 보면 이렇습니다.

브랜드별로 개별적인 분포도 볼 수 있습니다.

밀도로 시각화 해봤습니다.

분포를 한꺼번에 그릴 수도 있습니다.
1리터당가격이 6000원은 너무 비싸게 파는 것 같습니다.
용량도 총 리터도 얼마 안되는데 가격이 20000원이 넘습니다.

브랜드별로 1리터당가격 분포입니다.
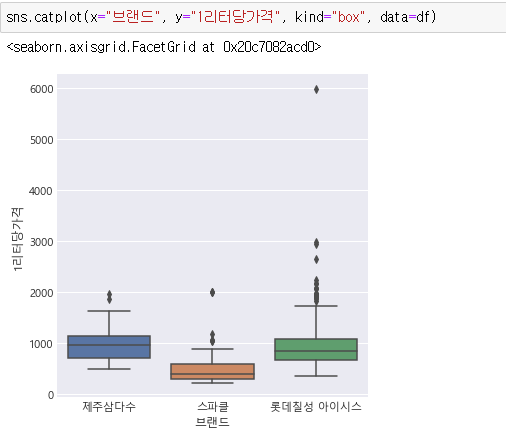
상자 그림으로 나타내면 깔끔합니다.

바이롤린 그림으로도 표현하면 분포도 알 수 있습니다.

브랜드별로 가격, 용량, 단위, 리터, 1리터당가격 모두 나타낼 수 있습니다.
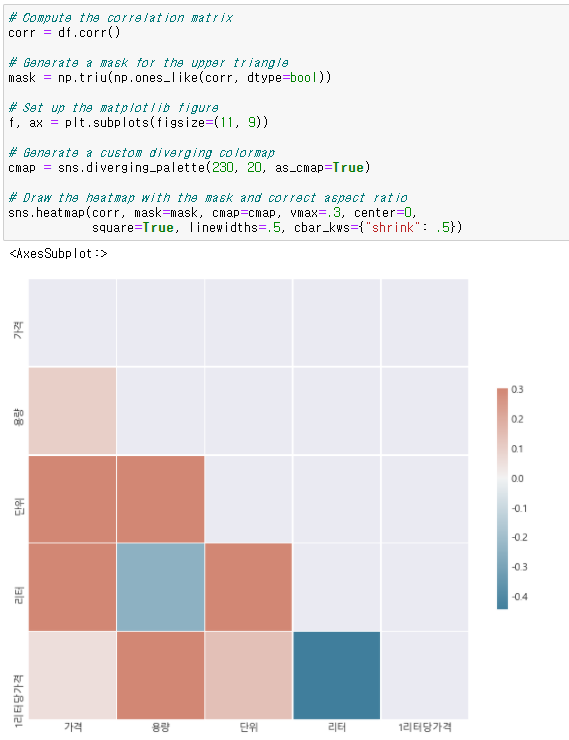
상관행렬입니다.
결론
EDA를 위해 각 변수들을 자세히 보고 시각화까지 해봤습니다.
시각화만 하고 끝내는 것이 아니라 도메인 지식을 바탕으로 가정했던 것이
실제 데이터에서 증명이 되는지 또는 새롭게 얻은 인사이트는 무엇인지 파악하는 것이 중요합니다.
예를 들어 스파클이 현재 다른 브랜드에 비해서 가격이 싼데 그 이유는 무엇인지 찾아보고
무슨 전략을 쓰고 있는지 파악해보는 등의 작업을 해 보는 것입니다.
'Python' 카테고리의 다른 글
| [데이터 가공, 정규표현식] G마켓 농심 라면 데이터 가공하기 Python (0) | 2021.07.23 |
|---|---|
| [크롤링] G마켓 농심 라면 데이터 수집 Python (0) | 2021.07.22 |
| [데이터 가공, 정규표현식] G마켓 생수 데이터 가공하기 Python (0) | 2021.07.19 |
| [크롤링] G마켓 생수 데이터 수집 Python (0) | 2021.07.18 |
| [로또] 처음 뽑은 6개의 번호를 제외한다면? (0) | 2021.07.17 |




댓글