안녕하세요. 인문계공돌이입니다.
오늘은 서울시 시내버스 노선별 일별 운행거리 데이터를 가지고 상관분석을 해보겠습니다.
데이터
데이터는 서울 열린데이터 광장에서 제공하는 서울시 시내버스 노선별 일별 운행거리입니다.

라이센스 및 다른 정보들은 위와 같습니다.
연구가설
서울시 시내버스 노선별 일별 운행거리 데이터 중 운행건수와 운행거리 간의 상관관계가 있는지 알아보겠습니다.
귀무가설 : 운행건수, 운행거리 간의 상관관계가 없다.
대립가설 : 운행건수, 운행거리 간의 상관관계가 있다.
상관분석

메뉴에서 분석 > 상관분석 > 이변량 상관계수를 클릭합니다.

변수에 운행건수와 운행거리를 넣고 확인을 눌러줍니다.

운행건수과 운행거리의 상관계수는 0.717 유의확률(양쪽)은 0.000입니다.
운행건수와 운행거리는 높은 정적 상관관계를 나타냈습니다.
진짜 연구 목적
사실 위의 분석은 너무나 당연합니다.
상식적으로 운행건수가 높으면 운행거리 또한 길어진다고 생각하기 때문입니다.
처음 생각엔 Pearson 상관계수가 1에 가깝게 나올 것이라 예측했는데
0.717로 다소 낮은 수치를 보였습니다.
이제부터 이 이유를 파헤치고자 합니다.
상관계수가 낮게 나온 이유
Python을 사용해서 하나하나 살펴보겠습니다.

데이터를 먼저 불러왔습니다.
어떤 노선이 과연 운행건수와 운행거리의 상관관계를 낮추는 데 영향을 미쳤는지 보겠습니다.

버스 노선명만 따로 list로 만들어 bus에 할당했습니다.

제일 위에 있는 3319를 살펴봤습니다.
그랬더니 운행일자가 한 개가 아니라 여러 개로 중복된 값들이 보입니다.
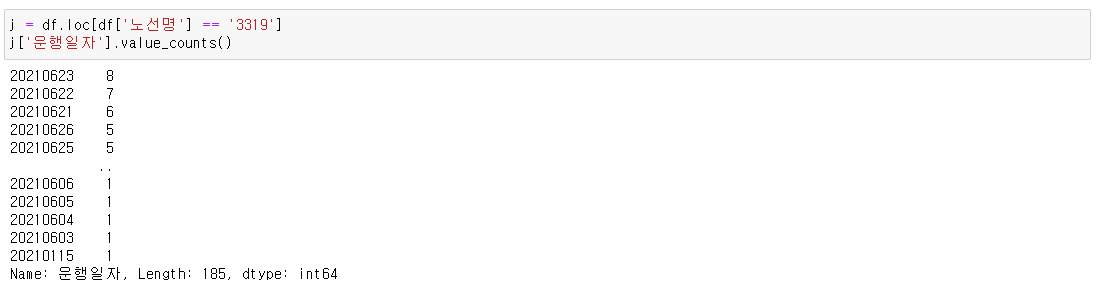
실제로 확인을 해봐도 그렇습니다.

때문에 중복된 값을 다 삭제했습니다.

이제 상관계수와 p-value 값을 추출하겠습니다.
예를 들어 3319의 상관계수와 p-value 값을 구해보면 0.999와 1.08e-304로 나옵니다.

반복문을 써서 노선명마다 상관계수와 p-value 값을 추출하고 따로 리스트로 저장했습니다.

이제 노선명, 상관계수, p-value를 dataframe 형식으로 저장했습니다.
여기서 또 처리를 해보겠습니다.

가장 먼저 결측치가 있나 찾아봤습니다.
12개가 있다고 나옵니다.
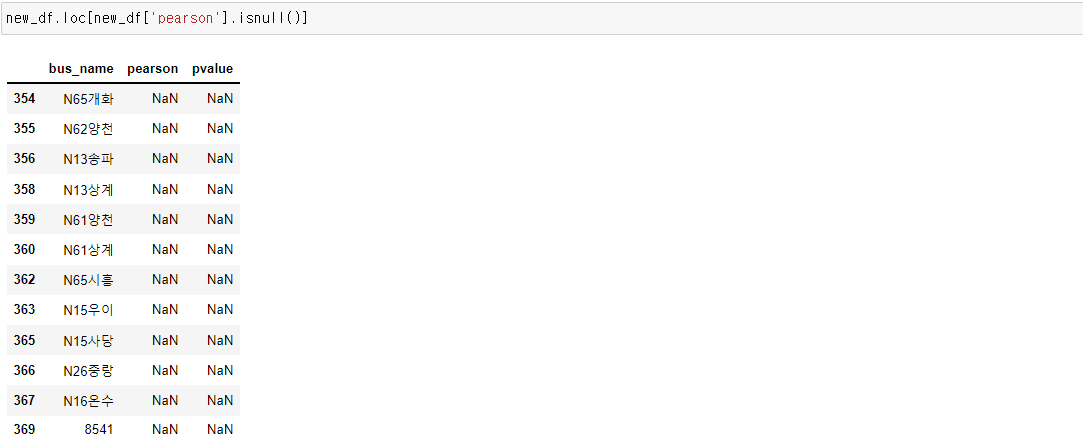
결측치에 해당하는 노선은 위와 같았고 왜 결측값인지 원본 데이터를 봤습니다.

이유는 바로 매 운행일자마다 운행건수와 운행거리가 똑같았기 때문입니다.

결측치가 있는 행은 삭제했습니다.

삭제하고 나서 이제 상관계수를 기준으로 오름차순 정렬 해주었습니다.
0.9이하인 것들의 이유를 찾아보겠습니다.
운행건수는 같지만 운행거리가 차이나서로 예상합니다.

총 16개입니다.
가장 낮은 것보터 하나 하나 보겠습니다.

가장 낮은 8221을 보면
예상대로 운행건수는 같지만 운행거리가 조금씩 차이 나서 상관계수가 낮았습니다.
또한 p-value 역시 0.05 이상이라 귀무가설을 기각하지 못합니다.
8112, 8551도 마찬가지였습니다.
일단 p-value 값이 0.05 이상이므로 이 노선명들은 삭제해주겠습니다.
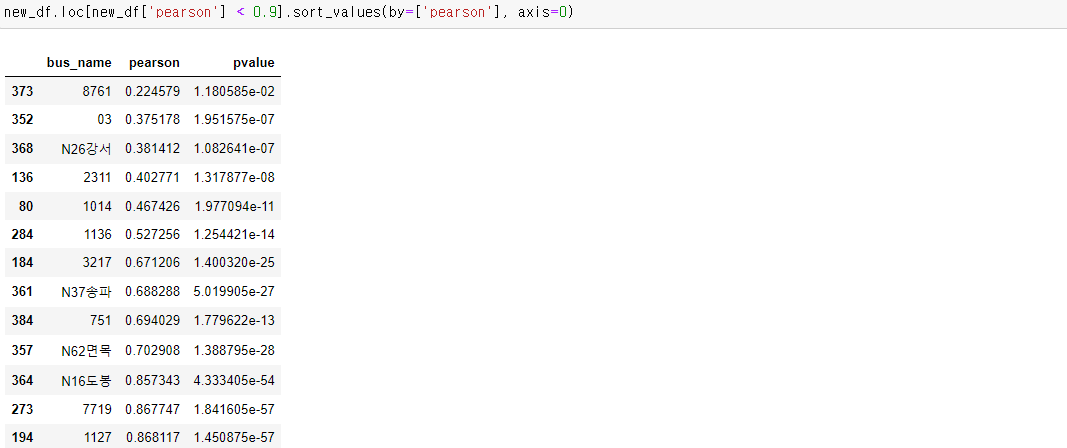
계속해서 살펴보겠습니다.
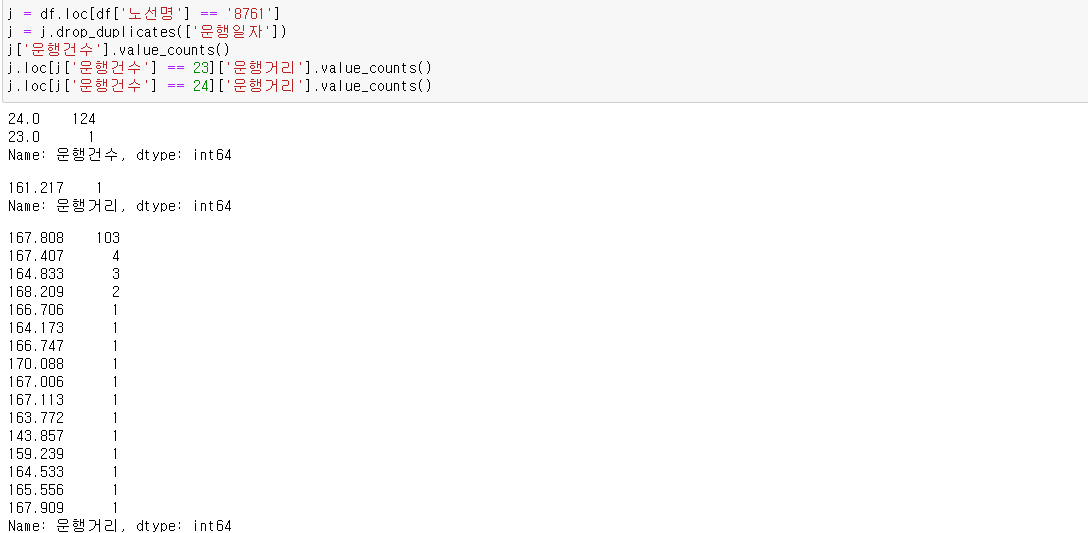
8761 역시 사정은 거의 비슷합니다.

상관계수가 0.375인 03 노선이 되어서야 드디어 운행건수가 다양해지기 시작합니다.

상관계수가 0.5가 넘는 1136 노선이 되면 운행건수가 엄청 많아집니다.

물론 상관계수가 0.85인 N16도봉은 운행건수 종류가 2개지만 운행건수 3과 4의 거리 차이가 확실합니다.
운행건수 4가 3보다 운행거리가 훨씬 많습니다.
상관계수가 0.22였던 8761 노선을 다시 복기해보면 운행건수가 23일 때는 운행거리가 161.217이었는데
운행건수가 24일 때도 143.857 같이 161보다 작은 값이 나타났습니다.
따라서 이제 상관관계가 0.7 이상만 남기고 아닌 노선을 지워 본 다음
상관분석을 다시 한 번 전체적으로 해보도록 하겠습니다.
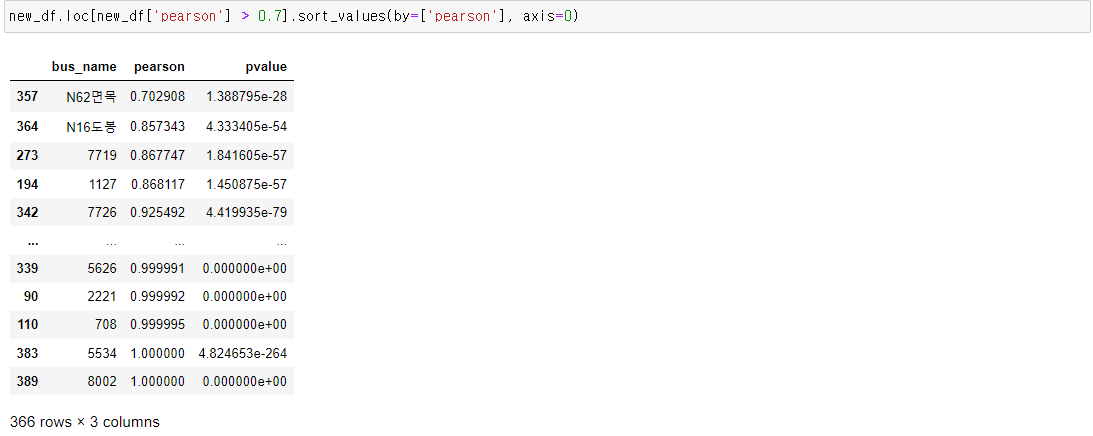
총 24개의 버스가 지워졌고
이 노선명만 이용해서 상관분석을 해보겠습니다.

해당 노선명만 리스트로 만들고

중복을 제거하여 새로운 dataframe에 추가했습니다.

노선 3319의 운행일자는 중복 값이 없습니다.

Python으로 해도 되지만 SPSS로 마무리 하겠습니다.

예측한 결과가 이제야 보입니다.
결론
유의확률이 0.05보다 낮았기 때문에
운행건수, 운행거리 간의 상관관계가 있습니다.
그것도 상관계수가 1이 나왔기 때문에 완벽한 양의 정적 관계이다로 파악하면 되겠습니다.
연구 결과가 예측한 바와 다르게 나오면 항상 데이터를 다시 살펴보고 클리닝 작업을 거치셔야 합니다.
'SPSS' 카테고리의 다른 글
| [독립표본 T 검정] 서울시 지하철호선별 역별 승하차 인원 정보 SPSS 분석 (0) | 2021.07.14 |
|---|---|
| [카이제곱 검정] 국가건강검진 시력데이터 SPSS 분석 (0) | 2021.07.13 |
| [판별분석] 국가건강검진 혈액검사데이터 SPSS 분석 (0) | 2021.07.11 |
| [판별분석] 국가건강검진 혈압혈당데이터 SPSS 분석 (0) | 2021.07.10 |
| [상관분석] 도로교통공단 일자별 시군구별 교통사고 건수 20191231 SPSS 분석 (0) | 2021.07.06 |




댓글