안녕하세요. 인문계공돌이입니다.
오늘은 공공자전거 이용정보(시간대별) 2021년 1월 데이터를 가지고 독립표본 T검정을 해보겠습니다.
데이터

데이터는 서울 열린데이터 광장에서 제공하는 서울특별시 공공자전거 이용정보(월별)입니다.

라이센스 및 다른 정보들은 위와 같습니다.
연구가설
귀무가설 : 2021년 1월 공공자전거는 대여구분코드에 따라 사용시간에 차이가 없을 것이다.
대립가설 : 2021년 1월 공공자전거는 대여구분코드에 따라 사용시간에 차이가 있을 것이다.
대여구분코드는 정기권과 일일권, 단체권으로 이루어져 있는데 이 중 정기권과 일일권만 사용하겠습니다.
독립표본 T검정

독립변수는 대여구분코드 종속변수는 사용시간입니다.

문자 그대로를 분석에서 사용할 수 없기에 자동 코딩변경을 통해 대여구분코드_숫자라는 변수를 새로 추가했습니다.
자동 코딩변경은 메뉴에서 변환 > 자동 코딩변경으로 들어가면 됩니다.

메뉴에서 분석 > 평균비교 > 독립표본 T 검정으로 들어가겠습니다.

검정변수 칸에는 종속변수인 사용시간을 집단변수 칸에는 독립변수인 대여구분코드_숫자를 넣어줍니다.
일일권, 정기권 집단만 사용할 것이기 때문에 집단정의를 눌러주세요.

저는 일일권은 2로, 정기권은 3으로 정의되어 있기 때문에 집단 1에 숫자 2를 집단 2에 숫자 3을 넣어주었습니다.
계속과 확인 버튼을 눌러주세요.
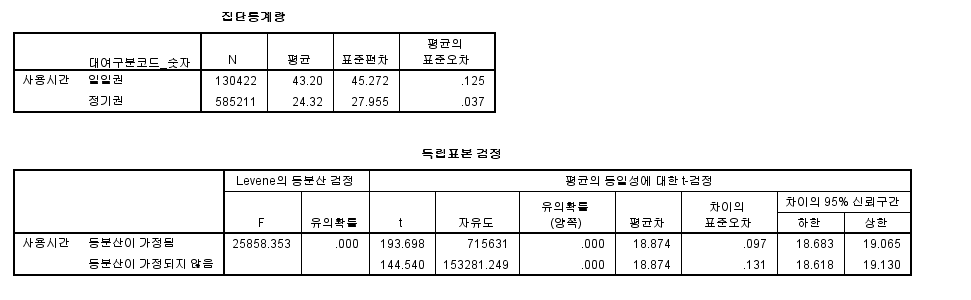
보고서를 보면 집단통계량 표와 독립표본 검정 표 2개가 나타납니다.
집단통계량 표에서는 두 집단 표본 수, 평균, 표준편차, 평균의 표준오차를 보여줍니다.
일일권과 정기권 모두 표본이 30개 이상이기 때문에 정규성을 만족한다고 할 수 있습니다.
평균을 보니 일일권의 평균 이용시간은 43.20시간, 정기권의 이용시간은 24.32시간으로 나타났습니다.

실제 두 집단의 평균 차이가 통계적으로 유의한지 보기 위해서 독립표본 검정 표를 보겠습니다.
Levene의 등분산 검정 F에서 유의확률이 0.000이므로 등분산을 가정하지 않게 됩니다.
따라서 등분산이 가정되지 않음을 기준으로 봐야 합니다.
독립표본 T 검정의 t=144.540, T 분포에 따른 유의확률(양쪽)은 0.000으로 나타났습니다.
즉, 유의확률(p) = 0.000 < 0.05 이므로
대립가설인 '2021년 1월 공공자전거는 대여구분코드에 따라 사용시간에 차이가 있을 것이다.'가 채택이 됩니다.
결론
2021년 1월에는 일일권과 정기권의 사용시간은 차이가 있음을 보였습니다.
일일권의 평균 사용시간이 정기권의 사용시간보다 많았습니다.
사용시간에서 차이가 나니 그에 알맞은 운영방법, 혜택이나 이벤트 등을 기획할 수 있겠습니다.
다른 년도 및 월에도 같은 결과가 나오는지 한 번 분석해 봐야겠습니다.
'SPSS' 카테고리의 다른 글
| [카이제곱 검정] 경기도 일자리 청년통장소득재산 SPSS 분석 (0) | 2021.06.29 |
|---|---|
| [독립표본 T 검정] 서울시농수산식품공사 품목별등급별가격(도매시장) SPSS 분석 (0) | 2021.06.28 |
| [독립표본 T 검정]서울시 대형마트 및 전통시장 달걀 10개 & 30개 가격 정보 21년 상반기 SPSS 분석 (0) | 2021.06.27 |
| 서울글로벌센터 월별 상담실적 SPSS 분석 (2) (0) | 2021.06.26 |
| 서울글로벌센터 월별 상담실적 SPSS 분석 (1) (0) | 2021.06.25 |




댓글